Degree Centrality
Degree centrality is defined as the number of edges incident upon a vertex (i.e., the number of ties that a node has).
One major application of degree centrality is in cybersecurity, and more generally, network management.
The degree can be interpreted in terms of the immediate risk of a node for catching whatever is flowing through the network (such as a virus, or some information).
Specifications
CREATE QUERY tg_degree_cent(SET<STRING> v_type, SET<STRING> e_type, SET<STRING> re_type, BOOL in_degree = TRUE, BOOL out_degree = TRUE, INT top_k=100, BOOL print_accum = True, STRING result_attr = "", STRING file_path = "")
Parameters
| Name | Description | Default value |
|---|---|---|
|
A set of vertex types. |
(empty set of strings) |
|
A set of edge types. |
(empty set of strings) |
|
A set of reverse edge types. If an edge is undirected, put the edge name in the set as well. |
(empty set of strings) |
|
Boolean value that indicates whether to count the incoming edges as part of a vertex’s degree centrality. |
True |
|
Boolean value that indicates whether to count the outgoing edges as part of a vertex’s degree centrality. |
True |
|
The number of vertices with the highest scores to return. |
100 |
|
If true, print results to JSON output. |
True |
|
If not empty, save the degree centrality score of each vertex to this attribute. |
(empty string) |
|
If not empty, save results in CSV to this file. |
(empty string) |
Example
Suppose we have the following graph:
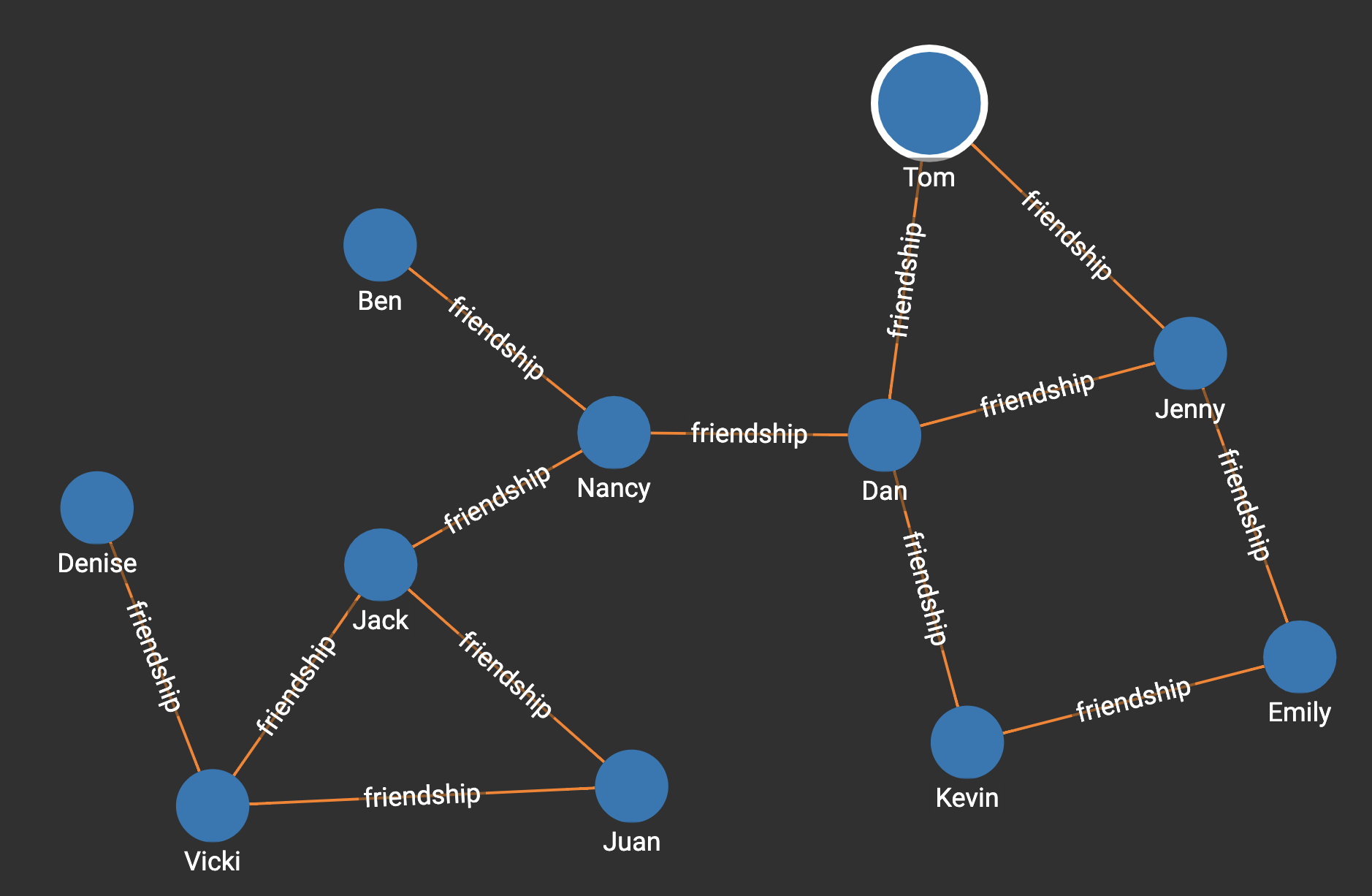
Running the query on the graph will show that Dan has the highest degree centrality:
RUN QUERY tg_degree_cent(["person"], ["friendship"],["friendship"])[
{
"top_scores": [
{
"Vertex_ID": "Dan",
"score": 4
},
{
"Vertex_ID": "Jenny",
"score": 3
},
{
"Vertex_ID": "Nancy",
"score": 3
},
{
"Vertex_ID": "Vicki",
"score": 3
},
{
"Vertex_ID": "Jack",
"score": 3
},
{
"Vertex_ID": "Juan",
"score": 2
},
{
"Vertex_ID": "Emily",
"score": 2
},
{
"Vertex_ID": "Kevin",
"score": 2
},
{
"Vertex_ID": "Tom",
"score": 2
},
{
"Vertex_ID": "Denise",
"score": 1
},
{
"Vertex_ID": "Ben",
"score": 1
}
]
}
]