Load from Cloud Storage
After you have defined a graph schema, you can create a loading job, specify your data sources, and run the job to load data.
The steps for loading from local files, cloud storage, or any other supported sources are similar. We will call out whether a particular step is common for all loading or specific to a data source or loading mode.
Example Schema
//Vertex Types:
CREATE VERTEX Person(PRIMARY_ID id UINT, firstName STRING, lastName STRING,
gender STRING, birthday DATETIME, creationDate DATETIME, locationIP STRING,
browserUsed STRING, speaks SET<STRING>, email SET<STRING>)
WITH STATS="OUTDEGREE_BY_EDGETYPE", PRIMARY_ID_AS_ATTRIBUTE="true"
CREATE VERTEX Comment(PRIMARY_ID id UINT, creationDate DATETIME,
locationIP STRING, browserUsed STRING, content STRING, length UINT)
WITH STATS="OUTDEGREE_BY_EDGETYPE", PRIMARY_ID_AS_ATTRIBUTE="true"
//Edge Types:
CREATE DIRECTED EDGE HAS_CREATOR(FROM Comment, TO Person)
WITH REVERSE_EDGE="HAS_CREATOR_REVERSE"Create Data Source Object
A data source object provides a standard interface for all supported data source types, so that loading jobs can be written without regard for the data source.
When you create the object, you specify its details (type, access credentials, etc.) in the form of a JSON object. The JSON object can either be read in from a file or provided inline.
|
Inline mode is required when creating data sources for TigerGraph Cloud instances. |
In the following example, we create a data source named s1, and read its configuration information from a file called ds_config.json.
USE GRAPH ldbc_snb
CREATE DATA_SOURCE s1 = "ds_config.json" FOR GRAPH ldbc_snb|
Older versions of TigerGraph required a keyword after |
CREATE DATA_SOURCE s1 = "{
type: <type>,
key: <value>
}" FOR GRAPH ldbc_snbString Literals
String literals can be represented according to the following options:
-
Enclosed with double quote
". -
Enclosed with triple double quotes
""". -
Enclosed with triple single quotes
'''.
In the case of JSON that does not contain a colon : or a comma , the double quotes " can be omitted.
CREATE DATA_SOURCE s1 = """{
"type": "<type>",
"key": "<value>"
}""" FOR GRAPH ldbc_snbEither a period . or _ can be used for separation in the specified key name. Example: first.second or first_second.
Three cloud source types are supported:
Also, three data object formats are supported: CSV, JSON, and Parquet.
AWS S3
The connector offers two methods for authentication:
-
The standard IAM credential provider using your access key
-
AWS Identity and Access Management (IAM) role associated with the EC2 instance
Access keys can be used for an individual user or for an IAM role. For the access key method, include the following fields in the data source connection:
{
"type": "s3",
"access.key": "<access key>",
"secret.key": "<secret key>"
}For the IAM role method, you must attach an IAM role to all the EC2 instances which constitute your TigerGraph database cluster. Include the following fields in the data source connection:
{
"type": "s3",
"file.reader.settings.fs.s3a.aws.credentials.provider": "com.amazonaws.auth.InstanceProfileCredentialsProvider",
"access.key": "none",
"secret.key": "none"
}
Beginning with v3.10.1, you may omit the access.key and secret.key fields if you are using the IAM role method.
|
For more information, see Amazon documentation on using IAM roles for Amazon EC2.
Temporary Credentials
In addition, AWS temporary credentials are supported. A temporary credential can be generated from the AWS CLI. For example:
aws sts assume-role --role-arn arn:aws:iam::<account-id>:role/<role> --role-session-name "<session-name>"For more details on temporary credentials, please refer to AWS documentation on temporary security credentials in IAM.
To use the temporary credential, add the below configurations in the data source definition:
{
"type": "s3",
"file.reader.settings.fs.s3a.aws.credentials.provider": "org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider",
"access.key": "The <AccessKeyId> in credential",
"secret.key": "The <SecretAccessKey> in credential",
"file.reader.settings.fs.s3a.session.token": "The <SessionToken> in credential"
}Example temporary credential from AWS
{
"Credentials": {
"AccessKeyId": "ASIA...X4M3A",
"SecretAccessKey": "/wSVO...WUZYv0",
"SessionToken": "IQoJb3J...O1k=",
"Expiration": "2024-10-10T23:00:00+00:00"
},
"AssumedRoleUser": {
"AssumedRoleId": "A...1",
"Arn": "arn:aws:sts::<acount>:assumed-role/<role-name>/<session-name>"
}
}Using MinIO (S3-Compatible Storage)
In 4.2.2, TigerGraph also supports loading data from MinIO, which is fully S3-compatible. When using MinIO instead of AWS S3, additional configuration is required.
Specify the MinIO Endpoint
Configure the S3A endpoint to point to your MinIO service:
"file.reader.settings.fs.s3a.endpoint": "<your_minio_endpoint>"The endpoint should resolve to your MinIO server and include the correct port if it is not using the default.
Enable Path-Style Access
MinIO typically requires path-style access instead of virtual-hosted–style access. Enable this option explicitly:
"file.reader.settings.fs.s3a.path.style.access": "true"Import MinIO TLS Certificates (Non-Public or Custom CA)
If your MinIO deployment uses non-public TLS certificates, such as:
-
Self-signed certificates
-
Certificates issued by an internal or private Certificate Authority (CA)
-
Certificates not included in the default Java trust store
you must import the MinIO root or CA certificate into TigerGraph’s Java trust store on all TigerGraph nodes.
Run the following command on each node:
JAVA_HOME=$(gadmin config get System.AppRoot)/.syspre/usr/lib/jvm/java-openjdk
$JAVA_HOME/bin/keytool -import -trustcacerts -alias certalias \
-noprompt \
-file /path/to/minio-root-cert \
-keystore $JAVA_HOME/lib/security/cacerts \
-storepass changeit
|
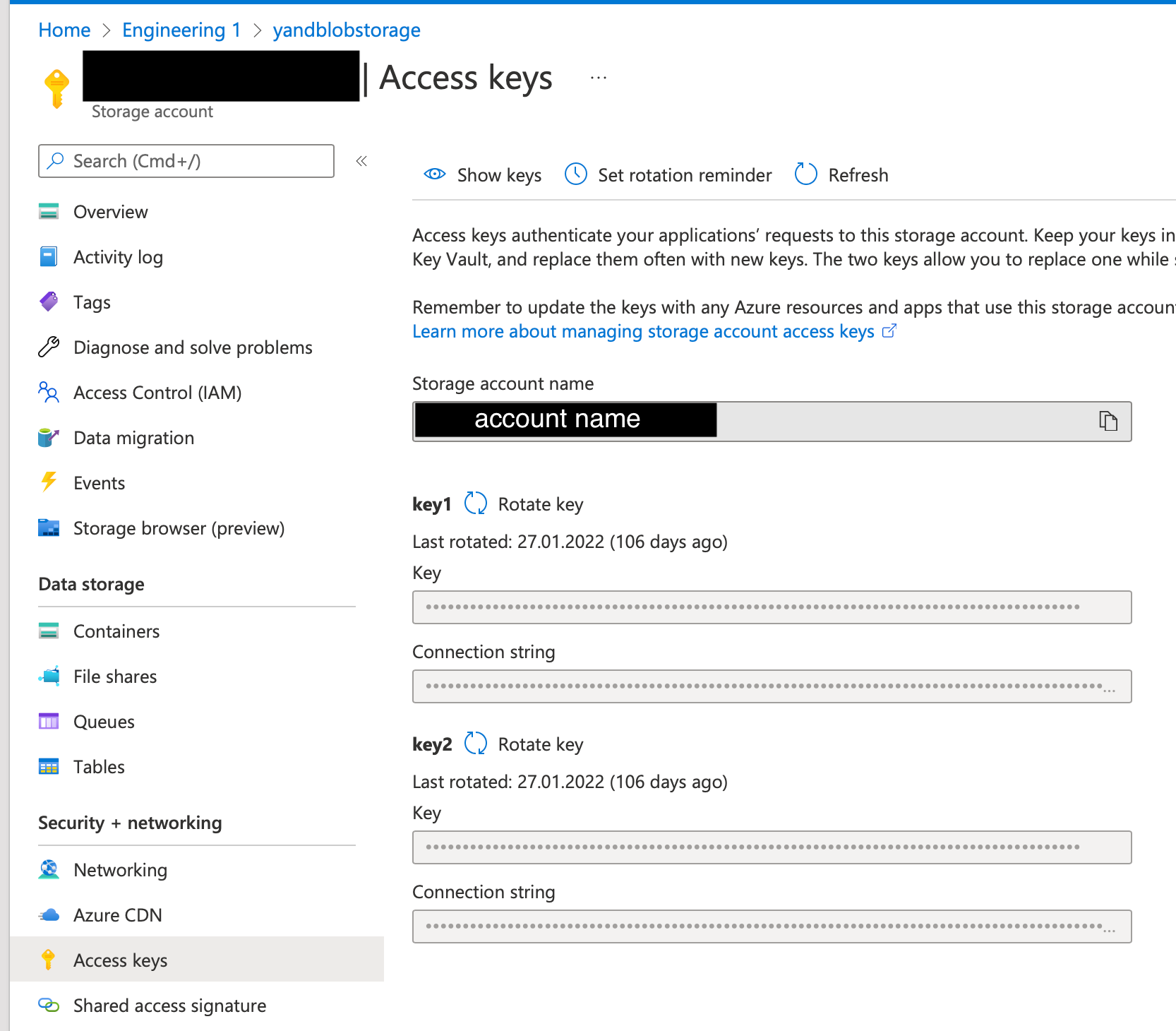
Azure Blob Storage
The connector supports two types of authentication:
Shared key authentication:
Get the account key on the Access Keys tab of your storage account. TigerGraph can automatically extract the account name from the file URI, so there’s no need to provide the account name.
{
"type" : "abs",
"account.key" : "<account key>"
}
Service principal authentication:
To use service principal authentication, you must first register your TigerGraph instance as an application and grant it access to your storage account.
{
"type" : "abs",
"client.id" : "<client id>",
"client.secret" : "<client secrect>",
"tenant.id" : "<tenant id>"
}Google Cloud Storage
For GCS, the TigerGraph data source configuration object is based on the GCS service account key format.
{
"type": "gcs",
"project_id": "<project id>",
"private_key_id": "<private key id>",
"private_key": "<private key>",
"client_email": "<email address>"
}You can follow Google Cloud’s instructions for creating a service account key, and then replace the "type" value with "gcs".
Create a loading job
A loading job tells the database how to construct vertices and edges from data sources. The loading job body has two parts:
-
DEFINE statements create variables to refer to data sources. These can refer to actual files or be placeholder names. The actual data sources can be given when running the loading job.
-
LOAD statements specify how to take the data fields from files to construct vertices or edges.
Example loading job from cloud storage
The following example uses AWS S3 as the source.
USE GRAPH ldbc_snb
CREATE LOADING JOB load_data FOR GRAPH ldbc_snb {
DEFINE FILENAME file_Comment =
"$s1:s3://s3-loading-test/tg_ldbc_snb/sf0.1_csv/dynamic/Comment";
DEFINE FILENAME file_Person =
"$s1:s3://s3-loading-test/tg_ldbc_snb/sf0.1_csv/dynamic/Person";
DEFINE FILENAME file_Comment_hasCreator_Person =
"$s1:s3://s3-loading-test/tg_ldbc_snb/sf0.1_csv/dynamic/Comment_hasCreator_Person";
LOAD file_Comment
TO VERTEX Comment
VALUES ($1, $0, $2, $3, $4, $5) USING header="true", separator="|";
LOAD file_Person
TO VERTEX Person
VALUES ($1, $2, $3, $4, $5, $0, $6, $7, SPLIT($8,";"), SPLIT($9,";"))
USING header="true", separator="|";
LOAD file_Comment_hasCreator_Person
TO EDGE HAS_CREATOR
VALUES ($1, $2) USING header="true", separator="|";
}Define filenames
First we define filenames, which are local variables referring to data files (or data objects).
The terms FILENAME and filevar are used for legacy reasons, but a filevar can also be an object in a data object store.
|
DEFINE FILENAME filevar ["=" file_descriptor ];The file descriptor can be specified at compile-time or at runtime. Runtime settings override compile-time settings:
RUN LOADING JOB job_name USING filevar=file_descriptor_override
While a loading job may have multiple FILENAME variables , they must all refer to the same DATA_SOURCE object.
|
Cloud file descriptors
For cloud sources, the file descriptor has three valid formats. You can simply provide the file URI. Or, you can provide optional configuration details, either in a JSON file or as inline JSON content.
DEFINE FILENAME file_name = "$[data source name]:[URI]";
DEFINE FILENAME file_name = "$[data source name]:[json config file]";
DEFINE FILENAME file_name = "$[data source name]:[inline json content]";See the following examples.
// Format 1: URI only
DEFINE FILENAME uri_s3 = "$s_s3:s3://s3-loading-test/tg_ldbc_snb/sf0.1_csv/dynamic/Comment";
DEFINE FILENAME uri_gcs = "$s_gcs:gs://tg_ldbc_snb/sf0.1_csv/dynamic/Person";
DEFINE FILENAME uri_abs = "$s_abs:abfss://person@yandblobstorage.dfs.core.windows.net/persondata.csv";
// Format 2: URI and configuration file
DEFINE FILENAME uri_s3 = "$s1:myfile.json";
// Format 3: URI and inline JSON
DEFINE FILENAME parquet_s3 = """$s1:{
"file.uris":"s3://s3-loading-test/tg_ldbc_snb/sf0.1_parquet/dynamic/Comment",
"file.type":"parquet"}""";
DEFINE FILENAME csv_gcs = """$s1:{
"file.uris": "gs://tg_ldbc_snb/sf0.1_csv/dynamic/Person",
"file.type": "text",
"num.partitions": 6}""";Filename parameters
These are the required and optional configuration parameters:
| Parameter | Description | Required? | Default value |
|---|---|---|---|
file.uris |
The URI or URIs separated by commas. |
Yes |
N/A |
file.type |
|
No |
If the file extension is |
batch.size |
The number of CSV lines or JSON objects that will be processed per batch. |
No |
10000 |
recursive |
If the URI refers to a directory, whether to search subdirectories recursively for files to load. |
No |
true |
regexp |
A regular expression to filter filenames to be loaded. Uses Java regular expression patterns. |
No |
.*, which permits all filenames. |
default |
The default value for any field left empty. |
No |
"", an empty string. |
archive.type |
The file type for archive files. Accepted values: |
No |
auto |
tasks.max |
The number of threads used to download data. |
No |
1 |
loading.timeout.ms |
The loading timeout per batch in milliseconds. If set to 0, then the global parameter |
No |
0 |
loading.max.retry.attempts |
The maximum number of retries after a retryable server error. 0 means an unlimited number of retries. |
No |
0 |
io.max.retry.attempts |
The maximum number of HTTP transport retries. 0 means an unlimited number of retries. |
No |
0 |
batch.size.bytes |
The maximum data batch size in bytes, overriding the Example: If each row of data is 1000b, |
No |
2,097,152 (2 MiB) |
num.partitions |
[Legacy: only used when gadmin parameter |
No |
3 |
|
Specify the data mapping
Next, we use LOAD statements to describe how the incoming data will be loaded to attributes of vertices and edges. Each LOAD statement handles the data mapping, and optional data transformation and filtering, from one filename to one or more vertex and edge types.
LOAD [ source_object|filevar|TEMP_TABLE table_name ]
destination_clause [, destination_clause ]*
[ TAGS clause ] (1)
[ USING clause ];| 1 | As of v3.9.3, TAGS are deprecated. |
Let’s break down one of the LOAD statements in our example:
LOAD file_Person TO VERTEX Person
VALUES($1, $2, $3, $4, $5, $0, $6, $7,
SPLIT($8, ";"), SPLIT($9, ";"))
USING SEPARATOR="|", HEADER="true", EOL="\n";-
$0,$1,… refer to the first, second, … columns in each line a data file. -
SEPARATOR="|"says the column separator character is the pipe (|). The default is comma (,). -
HEADER="true"says that the first line in the source contains column header names instead of data. These names can be used instead of the columnn numbers. -
SPLITis one of GSQL’s ETL functions. It says that there is a multi-valued column, which has a separator character to mark the subfields in that column.
Refer to Creating a Loading Job in the GSQL Language Reference for descriptions of all the options for loading jobs.
|
When loading JSON or Parquet data, please make sure:
E.g., |
Run the loading job
Use the command RUN LOADING JOB to run the loading job.
RUN LOADING JOB [-noprint] job_name [
USING filevar [="file_descriptor"][, filevar [="file_descriptor"]]*
[,EOF="eof_mode"]
]-noprint
By default, the loading job will run in the foreground and print the loading status and statistics after you submit the job.
If the -noprint option is specified, the job will run in the background after displaying the job ID and the location of the log file.
filevar list
The optional USING clause may contain a list of file variables. Each file variable may optionally be assigned a file_descriptor, obeying the same format as in CREATE LOADING JOB. This list of file variables determines which parts of a loading job are run and what data files are used.
When a loading job is compiled, it generates one RESTPP endpoint for each filevar and source_object. As a consequence, a loading job can be run in parts. When RUN LOADING JOB is executed, only those endpoints whose filevar or file identifier (GSQL_FILENAME_n) is mentioned in the USING clause will be used. However, if the USING clause is omitted, then the entire loading job will be run.
If a file_descriptor is given, it overrides the file_descriptor defined in the loading job. If a particular filevar is not assigned a file_descriptor either in the loading job or in the RUN LOADING JOB statement, an error is reported and the job exits.
Continuous Loading from Cloud Storage
EOF (End-of-file) is a boolean parameter.
The loader has two modes: streaming mode ("False") and EOF mode ("True").
Prior to version 3.9.2, the default value of EOF was "False".
Beginning with 3.9.2, the default value is "True".
-
If
EOF= "True" (EOF mode), loading will stop after consuming the provided file objects, i.e, when it reaches theEOFcharacter for each file object. -
If
EOF= "False" (streaming mode), the loading job remains active and keeps for new data until the job is aborted. The loader can detect both new lines in existing files and new files added to the designated source folder.
| Streaming mode checks for new content based on increased line number. Only new lines in existing files and new files will be loaded. If any existing lines are changed or deleted, these changes will not be part of the loading job. |
For example, consider a file data.txt in cloud storage
data.txtline-11) We load data.txt using streaming mode.
RUN LOADING JOB stream_csv USING EOF="false"The line of data is loaded successfully into the loading job for ingestion to TigerGraph.
2) If a user edits the file and adds a new line, the stream loader notices the addition and loads the new line, starting from where it previously left off.
data.txt after a line is addedline-1
line-2In this case, the new line line-2 is successfully ingested to TigerGraph,for a total of two lines.
3) If a user edits the file and inserts a line before the end, as shown below, the entire file is loaded again.
line-1
added-line
line-2Because two lines had already been loaded, the first two lines are skipped, even though the second contains new data. The third line from the file is then loaded, resulting in a repeat of line-2.
line-1
line-2
line-2| To insure data is loaded correctly, only use stream mode when there is no chance of data being altered or added to the middle of a file. |
Manage and monitor your loading job
When a loading job starts, the GSQL server assigns it a job ID and displays it for the user to see. There are four key commands to monitor and manage loading jobs:
SHOW LOADING STATUS job_id|ALL
ABORT LOADING JOB job_id|ALL
RESUME LOADING JOB job_id
SHOW LOADING ERROR job_idSHOW LOADING STATUS shows the current status of either a specified loading job or all current jobs, this command should be within the scope of a graph:
GSQL > USE GRAPH graph_name
GSQL > SHOW LOADING STATUS ALLFor each loading job, the above command reports the following information:
-
Loading status
-
Loaded lines/Loaded objects/Error lines
-
Average loading speed
-
Size of loaded data
-
Duration
When inspecting all current jobs with SHOW LOADING STATUS ALL, the jobs in the FINISHED state will be omitted as they are considered to have successfully finished. You can use SHOW LOADING STATUS job_id to check the historical information of finished jobs. If the report for this job contains error data, you can use SHOW LOADING ERROR job_id to see the original data that caused the error.
See Managing and Inspecting a Loading Job for more details.
Manage loading job concurrency
See Loading Job Concurrency for how to manage the concurrency of loading jobs.
Known Issues with Loading
| TigerGraph does not store NULL values. Therefore, your input data should not contain any NULLs. |
[3.9.2+] If the connector is manually deleted before reaching EOF, the corresponding loading job will never stop. Please use ABORT LOADING JOB to terminate the loading pipeline instead of directly manipulating the connector.