Data Streaming Connector
TigerGraph Data Streaming Connector is a Kafka connector that provides fast and scalable data streaming between TigerGraph and other data systems.
1. Architecture overview
Data Streaming Connector streams data from a source data system into TigerGraph’s internal Kafka cluster in the form of Kafka messages in specified topics. The messages are then ingested by a Kafka loading job and loaded into the database.
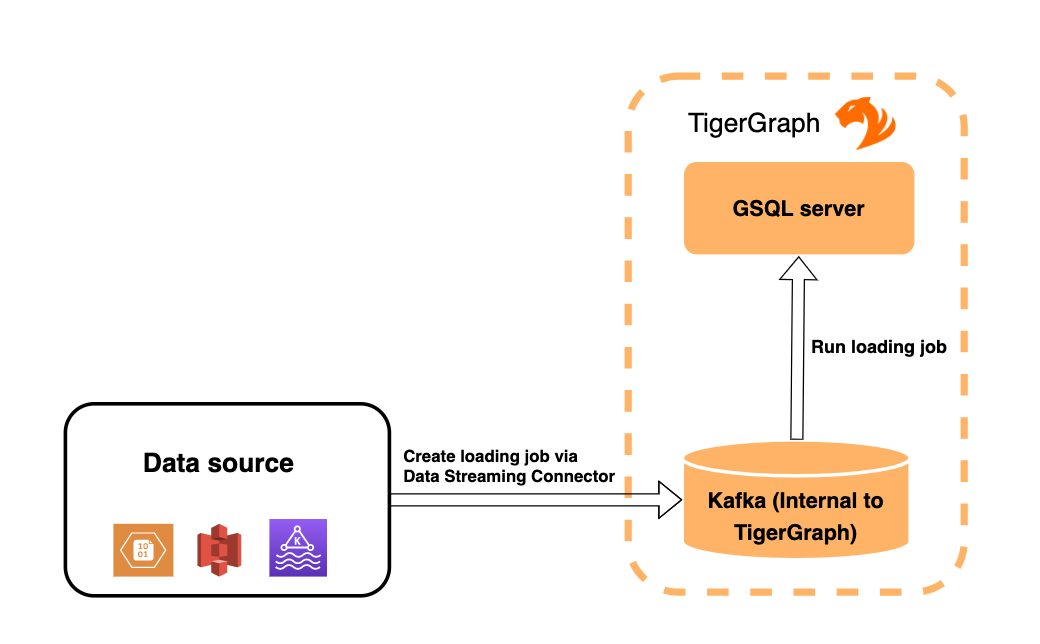
Multiple connectors can run at the same time, streaming data from various sources into the TigerGraph system concurrently.
3. Manage connectors
After creating a connector, you can choose to delete it or pause it.
You can also use gadmin commands to view status of all existing connectors.
3.1. List connectors
You can list all running connectors or view detailed configuration of a specific connector.
To view a list of all connectors, run gadmin connector list from your bash terminal as the TigerGraph Linux user.
To view configuration details of a specific connector, run gadmin connector list <name_of_connector> and replace <name_of_connector> with the name of the connector you want to inspect.
By default, this command displays most configurations of the connector, but redacts the credentials used to authenticate the connector.
If you use gadmin config to change the configuration parameter Controller.Connect.RedactSensitiveConfigValue to false , the command displays the connector’s authentication credentials.
3.2. Pause a connector
Pausing a connector stops the connector from streaming data from the data source. The data that has been streamed to TigerGraph’s internal Kafka can still be loaded into the graph store via a loading job.
To pause a connector, run the below command and replace <connector_name> with the name of the connector:
$ gadmin connector pause <connector_name>3.3. Resume a connector
Resuming a connector resumes streaming for a paused connector.
To resume a connector, run the below command and replace <connector_name> with the name of the connector:
$ gadmin connector resume <connector_name>3.4. Restart a connector
Restarting a connector is equivalent to pausing and then resuming a connector.
To restart a connector, run the below command and replace <connector_name> with the name of the connector:
$ gadmin connector restart <connector_name>3.5. Delete a connector
Deleting a connector removes a connector. It stops the connector from streaming, as well as deletes the data that has been streamed to the corresponding topics in Kafka that haven’t been ingested by a loading job. See the diagram in Figure 1 for details.
This does not delete the Kafka topics themselves, just the data in the topics associated to the connector. This also does not affect the data that has already been loaded into the database by a loading job, it only deletes the messages in TigerGraph’s internal Kafka server.
This action cannot be undone and a removed connector cannot be resumed.
When you create the same connector, with the same connector name and configurations, the connector loads all data from the source again to the same topics.
| There is a known issue for deleting connectors with created with folder URIs. Deleting the connector does not delete the connect offsets for topics that are mapped to a folder URI. If you create the same connector, with the same name and same URI to a folder, the connector only loads from where it left off before. A workaround for this issue is to create a connector with the same configurations, but with a different name. |
To delete a connector, run the below command and replace <connector_name> with the name of the connector:
$ gadmin connector delete <connector_name> -y (1)| 1 | You can use the -y option to skip the confirmation prompt. |
3.5.1. Save Kafka messages when deleting connector
When there are new files in a folder the connector streams from, you might want to recreate a connector for those file updates to be included. When you delete and recreate a connector, you can keep the messages that have already been streamed to the internal Kafka cluster. The recreated connector streams from where it left off before and does not duplicate data.
Use the -s or --soft flag to delete the connector only and leave the Kafka messages and offsets intact:
$ gadmin connector delete <connector_name> -s4. Known issues
| Automatic message removal is an Alpha feature and may be subject to change. |
Messages in TigerGraph’s internal Kafka cluster are automatically removed from the topics at regular intervals. There are several known issues with this process:
-
Messages are only removed if the loading job is actively running. If the loading job finishes much sooner before the interval is reached, the messages are not removed.
-
If loading job uses EOF mode, meaning the loading job will terminate as soon as it finishes, it is likely some partial data will be left in the topic.
-
If a topic is deleted and recreated while a loading job on the topic is running, the data in the topic may get removed.
-
Deleting the connector does not delete the connect offsets for topics that are mapped to a folder URI.
|
NULL is not a valid input value.
TigerGraph does not store NULL values. Therefore, your input data should not contain any NULLs. |