Stream Data from Azure Blob Storage
You can create a data connector between TigerGraph’s internal Kafka server and your Azure Blob Storage (ABS) with a specified topic. The connector streams data from data sources in your ABS containers to TigerGraph’s internal Kafka cluster.
You can then create and run a loading job to load data from Kafka into the graph store using the Kafka loader.
1. Prerequisites
-
You have an Azure storage account with access to the files you are streaming from.
| In the Data Protection section of the Azure portal, you must disable soft deletes for blobs. |
2. Procedure
2.1. Specify connector configurations
The connector configurations provide the following information:
-
Connector class
-
Your Azure Blob Storage account credentials
-
Information on how to parse the source data
-
Mapping between connector and source file
2.1.1. Connector class
connector.class=com.tigergraph.kafka.connect.filesystem.azure.AzureBlobSourceConnectorThe connector class indicates what type of connector the configuration file is used to create.
Connector class is specified by the connector.class key.
For connecting to ABS, its value is
connector.class=com.tigergraph.kafka.connect.filesystem.azure.AzureBlobSourceConnector.
2.1.2. Storage account credentials
You have two options when providing credentials:
Shared key authentication requires you to provide your storage account name and account key.
You can find both the account name and account key on the Access Key tab of your storage account:
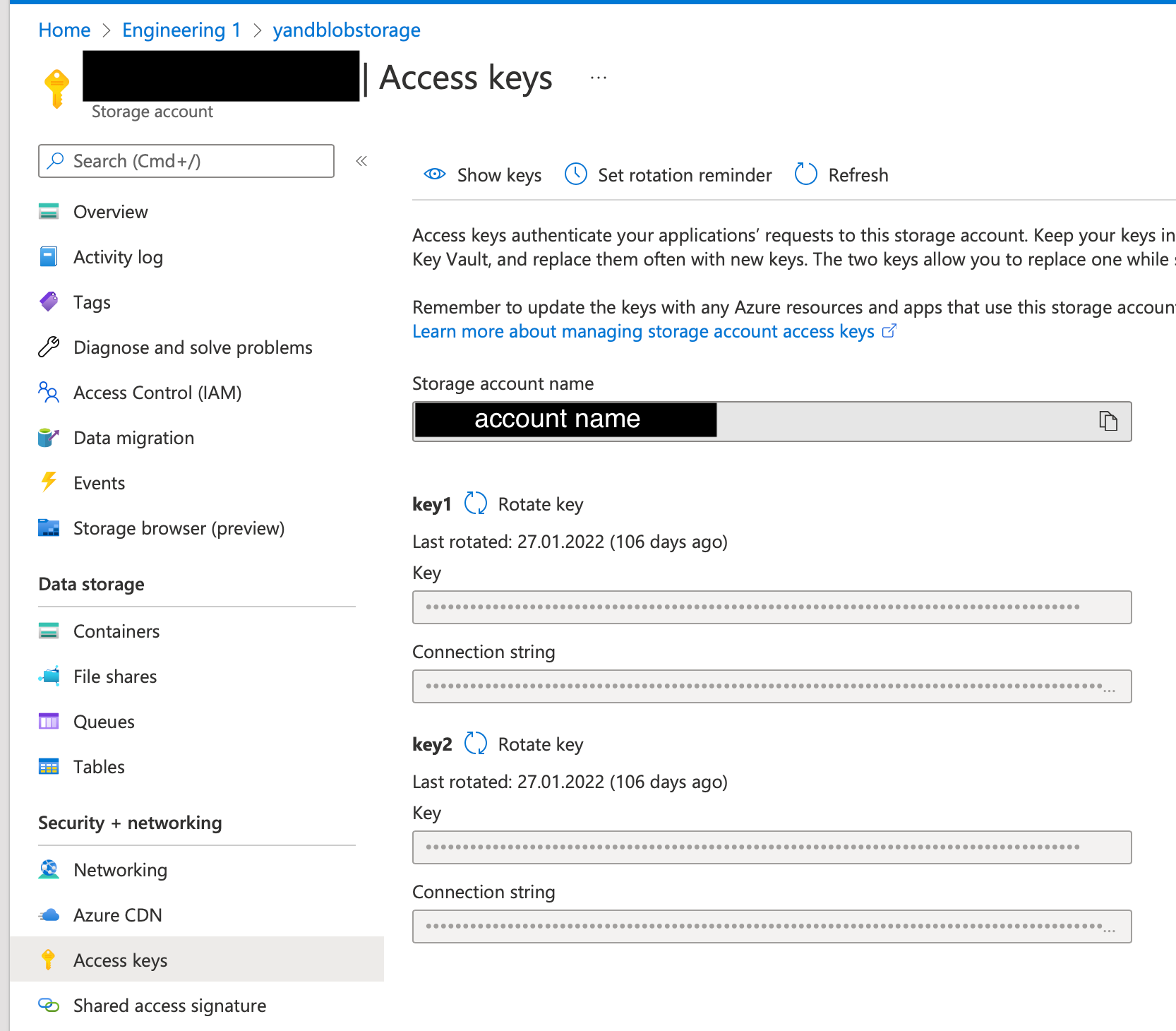
To specify the account name and key, use the following configuration.
Replace <account_name> with your account name and replace <account_key> with your account key:
file.reader.settings.fs.azure.account.key.<account_name>.dfs.core.windows.net="<account_key>"To use service principal authentication, you must first register your TigerGraph instance as an application and grant it access to your storage account.
Once the application is registered, you’ll need the following credentials:
-
CLIENT_ID -
CLIENT_SECRET -
TENANT_ID
Provide the credentials using the following configs:
file.reader.settings.fs.azure.account.oauth2.client.id="<client-ID>" file.reader.settings.fs.azure.account.oauth2.client.secret="<client-secret>" file.reader.settings.fs.azure.account.oauth2.client.endpoint="https://login.microsoftonline.com/<tenant-ID>/oauth2/token"
2.1.3. Other credentials
The connector uses Hadoop to connect to the Azure File system. The configurations below are required along with our recommended values:
file.reader.settings.fs.abfs.impl="org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem" file.reader.settings.fs.abfss.impl="org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem" file.reader.settings.fs.AbstractFileSystem.abfs.impl="org.apache.hadoop.fs.azurebfs.Abfs" file.reader.settings.fs.AbstractFileSystem.abfss.impl="org.apache.hadoop.fs.azurebfs.Abfss"
2.1.4. Specify parsing rules
The streaming connector supports the following file types:
-
CSV files.
-
Parquet files.
-
JSON files. Each JSON object must be on a separate line.
-
Directories.
-
tar files.
-
zip files.
For URIs that point to directories and compressed files, the connector looks for all files inside the directory or the compressed file that match the file.regexp parameter.
By default, this includes both CSV and JSON files.
If you set file.recursive to true, the connector looks for files recursively.
The following parsing options are available:
| Name | Description | Default |
|---|---|---|
|
The regular expression to filter which files to read. The default value matches all files. |
|
|
Whether to retrieve files recursively if the URI points to a directory. |
|
|
The type of file reader to use.
|
|
|
The character that separates columns. This parameter does not affect JSON files. |
|
|
The explicit boundary markers for string tokens, either single or double quotation marks. This parameter does not affect JSON files. The parser will not treat separator characters found within a pair of quotation marks as a separator. Accepted values:
|
Empty string |
|
The default value for a column when its value is null. This parameter does not affect JSON files. |
Empty string |
|
The maximum number of lines to include in a single batch. |
|
|
End of line character. |
|
|
Whether the first line of the files is a header line. If the value is set to true, the first line of the file is ignored during data loading. If you are using JSON files, set this parameter to false. |
|
|
File type for archive files.
Setting the value of this configuration to
|
|
|
If a file has this extension, treat it as a tar file |
|
|
If a file has this extension, treat it as a zip file |
|
|
If a file has this extension, treat it as a gzip file |
|
|
If a file has this extension, treat it as a |
|
2.1.5. Map source file to connector
The below configurations are required:
| Name | Description | Default |
|---|---|---|
|
Name of the connector. |
None. Must be provided by the user. |
|
Name of the topic to create in Kafka. |
None. Must be provided by the user. |
|
The maximum number of tasks which can run in parallel. |
1 |
|
Number of partitions in the topic used by connector. This only affects newly created topics and is ignored if a topic already exists. |
1 |
|
The path(s) to the data files on Google Cloud Storage. The URI may point to a CSV file, a zip file, a gzip file, or a directory |
None. Must be provided by the user. |
URIs for files must be configured in the following way:
<protocol: abfss | abfs>://<container name>@<accountname>.dfs.core.windows.net/<path to the file>
For example:
abfss://person@yandblobstorage.dfs.core.windows.net/persondata.csv
2.1.6. Example
The following is an example configuration file:
connector.class=com.tigergraph.kafka.connect.filesystem.azure.AzureBlobSourceConnector file.reader.settings.fs.defaultFS="abfss://example_container@example_account.dfs.core.windows.net/" file.reader.settings.fs.azure.account.auth.type="OAuth" file.reader.settings.fs.azure.account.oauth.provider.type="org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider" file.reader.settings.fs.azure.account.oauth2.client.id="<example>" file.reader.settings.fs.azure.account.oauth2.client.secret="<example>" file.reader.settings.fs.azure.account.oauth2.client.endpoint="https://login.microsoftonline.com/<example>/oauth2/token" file.reader.settings.fs.abfs.impl="org.apache.hadoop.fs.azurebfs.AzureBlobFileSystem" file.reader.settings.fs.abfss.impl="org.apache.hadoop.fs.azurebfs.SecureAzureBlobFileSystem" file.reader.settings.fs.AbstractFileSystem.abfs.impl=""org.apache.hadoop.fs.azurebfs.Abfs file.reader.settings.fs.AbstractFileSystem.abfss.impl="org.apache.hadoop.fs.azurebfs.Abfss" mode=eof file.regexp=".*" file.recursive=true file.reader.type=text file.reader.batch.size=10000 file.reader.text.eol="\\n" file.reader.text.header=true file.reader.text.archive.type=auto file.reader.text.archive.extensions.tar=tar file.reader.text.archive.extensions.zip=zip file.reader.text.archive.extensions.gzip=tar.gz,tgz [azure_connector_person] name = azure-fs-person-demo-104 tasks.max=10 topic=azure-fs-person-demo-104 file.uris=abfss://example_container@example_account.dfs.core.windows.net/persondata.csv
2.2. Create connector
Once you have prepared the configuration file, run command gadmin connector create and specify the configuration file to create the connector:
gadmin connector create --c <config_file>The connectors start streaming from the data source immediately after creation if the configurations are valid.
You can run gadmin connector status to verify the status of the connectors.
If the configurations are valid, the connectors should be in RUNNING status.
Data streamed from the source stays in the destination cluster Kafka topics.
If the destination cluster is TigerGraph’s internal Kafka cluster, the messages are removed as they are loaded in to the graph during the course of the loading job at regular intervals.
|
Automatic removal of loaded Kafka messages is an alpha feature and may be subject to change. |
2.3. Create data source
Now that the connector has started loading data into TigerGraph’s internal Kafka cluster, you can create a data source and point it to the Kafka cluster:
-
Create a data source configuration file. The only required field is the address of the broker. The broker’s IP and hostname is the private IP of your TigerGraph server and port of TigerGraph’s internal Kafka server:
-
If you don’t know your private IP, you can retrieve it by running
gmyipin the bash terminal. -
To retrieve the port of your Kafka cluster, run
gadmin config get Kafka.Portto retrieve the port number. The default port is30002.
In the
kafka.configfield, you can provide additional configurations from librdkafka Global Configurations. For example, you can specifygroup.idto betigergraphto specify the group that this consumer belongs to:{ "broker":"10.128.0.240:30002", (1) "kafka_config": { "session.timeout.ms":"20000" } }1 Make sure to use the internal ID of the machine instead of localhostfor the hostname of the broker.localhostonly works for single-server instances. -
-
Run
CREATE DATA SOURCEto create the data source and assign the configuration file to the data source you just created:CREATE DATA_SOURCE KAFKA <datasource_name> FOR GRAPH <graph_name> SET <datasource_name> = <path_to_datasource_config>For example:
CREATE DATA_SOURCE KAFKA k1 FOR GRAPH Social SET k1 = "/home/tigergraph/social/k1.config"
2.4. Create loading job
Create a loading job to load data from the data source:
-
Create a topic-partition configuration for each topic.
{ "topic": <topic_name>, (1) "partition_list": [ (2) { "start_offset": <offset_value>, (3) "partition": <partition_number> (4) }, { "start_offset": <offset_value>, (3) "partition": <partition_number> (4) } ... ] }1 Replace <topic_name>with the name of the topic this configuration applies to. This must be one of the topics you configured in the connector configuration step.2 List of partitions you want to stream from. For each partition, you can set a start offset. If this list is empty, or partition_listisn’t included, all partitions are used with the default offset.3 Replace <offset_value>with the offset value you want. The default offset for loading is-1, which means you will load data from the most recent message in the topic. If you want to load from the beginning of a topic, thestart_offsetvalue should be-2.4 Replace <partition_number>with the partition number if you want to configure. -
Create a loading job and map data to graph. See Kafka loader guide for how to map data from a Kafka data source to the graph. See Loading JSON data on how to create a loading job for JSON data.
Known bug: to use the -1 value for offset, delete the start_offset key instead of setting it to -1.
|
For example, suppose we have the following two CSV files and schema:
CREATE VERTEX Person (PRIMARY_ID name STRING, name STRING, age INT, gender STRING, state STRING)
CREATE UNDIRECTED EDGE Friendship (FROM Person, TO Person, connect_day DATETIME)
CREATE GRAPH Social (Person, Friendship)name,gender,age,state
Tom,male,40,ca
Dan,male,34,ny
Jenny,female,25,tx
Kevin,male,28,az
Amily,female,22,ca
Nancy,female,20,ky
Jack,male,26,fl
A,male,29,caperson1,person2,date
Tom,Dan,2017-06-03
Tom,Jenny,2015-01-01
Dan,Jenny,2016-08-03
Jenny,Amily,2015-06-08
Dan,Nancy,2016-01-03
Nancy,Jack,2017-03-02
Dan,Kevin,2015-12-30
Amily,Dan,1990-1-1The following topic-partition configurations and loading job will load the two CSV files into the graph:
{
"topic": "person-demo-104",
"partition_list": [
{
"start_offset": -2,
"partition": 0
}
]
}{
"topic": "friend-demo-104",
"partition_list": [
{
"start_offset": -2,
"partition": 0
}
]
}CREATE LOADING JOB load_person FOR GRAPH Social {
DEFINE FILENAME f1 = "$k1:/home/mydata/topic_person.json"; (1)
DEFINE FILENAME f2 = "$k1:/home/mydata/topic_friend.json";
LOAD f1 TO VERTEX person VALUES ($0, $0, $2, $1, $3) USING separator=",";
LOAD f2 TO EDGE friendship VALUES ($0, $1, $2) USING separator=",";
}| 1 | $k1 refers to a data source defined in the graph.
See Create data source |
2.5. Run loading job
Run the loading job created in the last step will load the streamed data into the graph.
If you make changes to the topic-partition configuration file, you can overwrite the values for the filename variables with the USING clause.
GSQL > RUN LOADING JOB load_personBy default, loading jobs that use Kafka data sources run in streaming mode and do not stop until manually aborted. As data is streamed from the data source, the running loading job will continuously ingest the streamed data into the graph store.