Data Loading Overview
Once you have defined a graph schema, you can load data into the graph. This section focuses on how to configure TigerGraph for the different data sources, as well as different data formats and transport schemes.
Data Sources
You have several options for data sources:
-
Local Files: Files residing on a TigerGraph server can be loaded without the need to create a GSQL DATA_SOURCE object. This option can have the highest performance.
-
Outside Sources: Loading data from an outside source, such as cloud storage, requires one additional step to first define a DATA_SOURCE object, which uses the Kafka Connect framework. Kafka offers a distributed, fault-tolerant, real-time data pipeline with concurrency. By encapsulating the details of the data source connection in a DATA_SOURCE object, GSQL can treat the source like it treats a local file. You can use this approach for the following data sources:
-
Cloud storage (Amazon S3, Azure Blob Storage, Google Cloud Storage)
-
Data warehouse query results (Google BigQuery)
-
External Kafka cluster
See the pages for the specific method that fits your data source.
-
-
Spark/JDBC: To load data from other big data platforms, such as Hadoop, the typical method is to use Spark’s built-in feature to write a DataFrame to a JDBC target, together with TigerGraph’s
POST /ddlREST endpoint.
Loading Workflow
TigerGraph uses the same workflow for both local file and Kafka Connect loading:
-
Specify a graph. Data is always loading to exactly one graph (though that graph could have global vertices and edges which are shared with other graphs). For example:
USE GRAPH ldbc_snb -
If you are using Kafka Connect, define a
DATA_SOURCEobject. See the details on the pages for cloud storage, BigQuery, or an external Kafka cluster. -
Create a loading job.
-
Run your loading job.
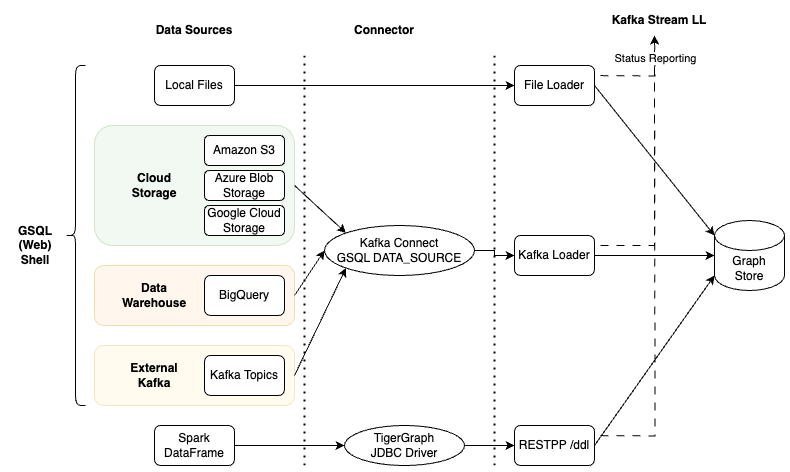
Loading System Architecture
This diagram shows the supported data sources, which connector to use, and which TigerGraph component manages the data loading.
Loading Jobs
A loading job tells the database how to construct vertices and edges from data sources.
CREATE LOADING JOB <job_name> FOR GRAPH <graph_name> {
<DEFINE statements>
<LOAD statements>
}The opening line does some naming:
-
assigns a name to this job: (
<job_name>) -
associates this job with a graph (
<graph_name>)
The loading job body has two parts:
-
DEFINE statements create variables to refer to data sources. These can refer to actual files or be placeholder names. The actual data sources can be given when running the loading job.
-
LOAD statements specify how to take the data fields from files to construct vertices or edges.
| Refer to the Creating a Loading Job documentation for full details |