Kafka Loader User Guide
Kafka is a popular pub-sub system in enterprise IT, offering a distributed and fault-tolerant real-time data pipeline. The Kafka Loader lets you integrate TigerGraph with a Kafka cluster and speed up your real-time data ingestion. The Kafka Loader is easily extensible using the many plugins available in the Kafka ecosystem.
The Kafka Loader consumes data in a Kafka cluster and loads data into the TigerGraph system. It supports all the data source formats supported by GSQL loading jobs, which includes JSON, CSV, and Parquet.
Architecture
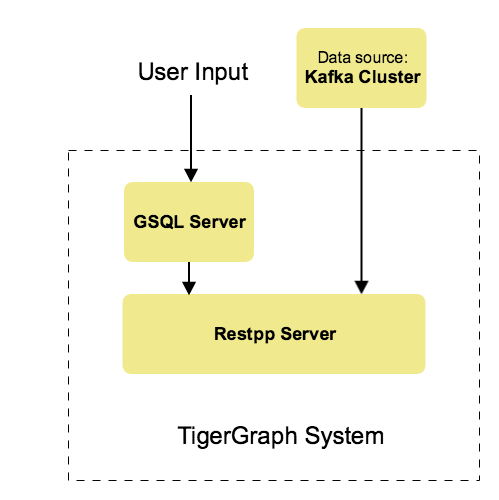
From a high level, a user provides instructions to the TigerGraph system through GSQL, and the external Kafka cluster loads data into TigerGraph’s RESTPP server. The following diagram demonstrates the Kafka Loader data architecture.
Currently, the Kafka loader doesn’t use consumer groups.
If the loader is interrupted, you have to resume the loading job manually by running RESUME LOADING JOB job_id.
This resumes the loading job where it was interrupted.
|
Supported file formats
-
CSV
-
JSON
If the Kafka loader fails to parse messages due to formatting issues, the Kafka Loader skips the messages the fail to be parsed.
Prerequisites
-
Your TigerGraph instance has access to a running external Kafka cluster.
-
Once you have the external Kafka cluster set up, prepare the following two configuration files and place them in your desired location in the TigerGraph system:
Kafka data source configuration file
The data source configuration file’s content, structured as a JSON object, describes the Kafka server’s global settings, including the data source IP address and port.
A sample kafka.conf is shown in the following example:
{
"broker": "192.168.1.11:9092"
}The broker key is required, and its value is a fully qualified domain name (or IP) and port.
Additional Kafka configuration parameters may be provided (see Kafka documentation) by using the optional "kafka_config" key.
For its value, provide a list of key-value pairs.
For example:
{
"broker": "localhost:9092",
"kafka_config": {"group.id":"tigergraph"}
}Kafka topic and partition configuration file
The topic-partition configuration file tells the TigerGraph system exactly which Kafka records to read. Similar to the data source configuration file described above, the contents are in JSON object format.
There are two root-level fields in the configuration file:
topic-
Required. Specifies the Kafka topic to read from.
partition_list-
Optional. Specifies which topic partitions to read and what start offsets to use. If the
partition_listkey is missing or empty, all partitions in this topic will be used for loading. The default offset for loading is-1, which means you will load data from the most recent message in the topic, that is, the end of the topic. If you want to load from the beginning of a topic, thestart_offsetvalue should be-2.
An example file is shown below:
{
"topic": "topicName1",
"partition_list": [
{
"start_offset": -1,
"partition": 0
},
{
"start_offset": -1,
"partition": 1
},
{
"start_offset": -1,
"partition": 2
}
]
}You can also overwrite the default offset by setting "default_start_offset" in the Kafka topic configuration file.
For example,
{
"topic": "topicName1" (1)
}
{
"topic": "topicName1",
"partition_list": [] (1)
}
{
"topic": "topicName1",
"default_start_offset": 0 (2)
}| 1 | All partitions will be used if the config file doesn’t provide partition_list or if the partition list is empty. |
| 2 | This overwrites the default start offset to 0. |
Configure and use the Kafka loader
The following are the steps to load data into your TigerGraph database through the Kafka loader:
The GSQL syntax for the Kafka Loader is designed to be consistent with the existing GSQL loading syntax.
1. Define the data source
Before starting a Kafka data loading job, you need to define the Kafka server as a data source.
The CREATE DATA_SOURCE statement defines a data source variable with a subtype of KAFKA:
GSQL > CREATE DATA_SOURCE KAFKA example_data_sourceAfter the data source is created, then use the SET command to specify the path to a configuration file for that data source.
Each time when the config file is updated, you must run SET example_data_source to update the data source details in the dictionary.
GSQL > SET example_data_source = "/path/to/kafka.config" (1)| 1 | If you have a TigerGraph cluster, the configuration file must be on machine m1, where the GSQL server and GSQL client both reside, and it must be in JSON format. If the configuration file uses a relative path, the path should be relative to the GSQL client working directory. |
For simplicity, you can merge the CREATE DATA_SOURCE and SET statements:
GSQL > CREATE DATA_SOURCE KAFKA data_source_name = "/path/to/kafka.config"To further simplify, instead of specifying the Kafka data source config file path, you can also directly provide the Kafka data source configuration as a string argument, as shown below:
GSQL > CREATE DATA_SOURCE KAFKA data_source_name = "{\"broker\":\"broker.full.domain.name:9092\"}"|
The above simplified statement is useful for using Kafka Data Loader in TigerGraph Cloud. In TigerGraph Cloud, you can use the GSQL web shell to define and create Kafka data sources without creating the Kafka data source configuration file in the filesystem. |
2. Create a loading job
The Kafka Loader uses the same CREATE LOADING JOB syntax used for standard GSQL loading jobs.
A DEFINE FILENAME statement should be used to assign a FILENAME variable to a Kafka data source name and the path to its config file.
In addition, the filename can be specified in the RUN LOADING JOB statement with the USING clause.
The filename value set by a RUN statement overrides the value set in the CREATE LOADING JOB.
| If you are loading JSON data, the data needs to be in the JSON lines format instead of regular JSON. |
Syntax
In the syntax, $DATA_SOURCE_NAME is the Kafka data source name, and the path points to a configuration file with topic and partition information of the Kafka server.
The Kafka configuration file must be in JSON format.
DEFINE FILENAME filevar "=" [filepath_string | data_source_string];
data_source_string = $DATA_SOURCE_NAME":"<path_to_configfile>Example
The following statement loads a Kafka data source k1, where the path to the topic-partition configuration file is "~/topic_partition1_conf.json":
DEFINE FILENAME f1 = "$k1:~/topic_partition_config.json";Instead of specifying the config file path, you can also provide the topic-partition configuration as a string argument, as shown below:
DEFINE FILENAME f1 = "$k1:~/topic_partition_config.json";
DEFINE FILENAME f1 = "$k1:{\"topic\":\"zzz\",\"default_start_offset\":2,\"partition_list\":[]}";3. Run the loading job
The Kafka Loader uses the same RUN LOADING JOB statement that is used for GSQL loading from files.
Each filename variable can be assigned a string <data_source_name>:<topic_partition_configuration_filepath>, which will override the value defined in the loading job.
In the example below, the config files for f3 and f4 are being set by the RUN command, whereas f1 is using the config which was specified in the CREATE LOADING JOB statement.
RUN LOADING JOB job1 USING f1, f3="$k1:~/topic_part3_config.json", f4="$k1:~/topic_part4_config.json", EOF="true";|
A For example, you may not mix both Kafka data sources and regular file data sources in one loading job. |
All filename variables in one loading job statement must refer to the same DATA_SOURCE variable.
There are two modes for the Kafka Loader: streaming mode and EOF mode. The default mode is streaming mode. In streaming mode, loading will never stop until the job is aborted. In EOF mode, loading will stop after consuming the current Kafka message.
To set EOF mode, an optional parameter is added to the RUN LOADING JOB syntax:
RUN LOADING JOB [USING (<using-param> | <using-param> [, <using-param>]*)]
<using-param> ::= filevar [="filepath_string"] | CONCURRENCY="cnum" | BATCH_SIZE="bnum" | EOF=("true"|"false")To learn about each option and parameter of the RUN LOADING JOB command, see Loading job options.
The Kafka Loader parameter KafkaLoader.ReplicaNumber controls the number of Kafka Loader replicas per node.
The default is 1, which means only one loading job can be run at a time. To run multiple loading jobs at the same time, increase this parameter.
Examples
Here is an example code for loading CSV data through Kafka Loader:
// Create data_source kafka k1 = "kafka_config.json" for graph test_graph
CREATE DATA_SOURCE KAFKA k1 FOR GRAPH test_graph
SET k1 = "kafka_config.json"
// Define the loading jobs
CREATE LOADING JOB load_person FOR GRAPH Test_Graph {
DEFINE FILENAME f1 = "$k1:topic_partition_config.json";
LOAD f1
TO VERTEX Person VALUES ($2, $0, $1),
TO EDGE Person2Comp VALUES ($0, $1, $2)
USING SEPARATOR=",";
}
// Load the data
RUN LOADING JOB load_personThe following example loading job loads JSON data through the Kafka loader:
CREATE LOADING JOB kafka_loader_json FOR GRAPH Store_Graph {
DEFINE FILENAME users = "$kafkaLoader:/home/tigergraph/config/topic-users.config";
DEFINE FILENAME transactions =
"$kafkaLoader:/home/tigergraph/config/topic-transactions.config";
LOAD users TO VERTEX User VALUES
($"payload":"userid", $"payload":"regionid", $"payload":"gender") USING JSON_FILE="true"; (1)
LOAD transactions TO EDGE hasTransaction VALUES
($"payload":"user_id", $"payload":"transaction_id") USING JSON_FILE="true";
LOAD transactions TO VERTEX transaction VALUES
($"payload":"transaction_id", $"payload":"card_id", $"payload":"user_id", $"payload":"purchase_id", $"payload":"store_id")
USING JSON_FILE="true";
}| 1 | The userid field of the payload field is loaded to the first attribute in the User vertex type definition.
The regionid field of the payload field is loaded to the second attribute in the User vertex type definition.
For more information on loading JSON data, see Loading JSON data. |
Manage data sources
A data source can be either global or local:
-
A global data source can only be created by a user with
WRITE_DATASOURCEprivilege on the global scope, who can grant it to any graph. -
A local data source belongs to a graph and cannot be accessed by other graphs.
The following are examples of permitted DATA_SOURCE operations.
-
Users with the
WRITE_DATASOURCEprivilege on the global scope may create a global level data source without assigning it to a particular graph:
GSQL > CREATE DATA_SOURCE KAFKA k1 = "/path/to/config"-
Users with the
WRITE_DATASOURCEprivilege on the global scope may grant/revoke a data source to/from one or more graphs:
GSQL > GRANT DATA_SOURCE k1 TO GRAPH graph1, graph2
GSQL > REVOKE DATA_SOURCE k1 FROM GRAPH graph1, graph2-
Users with the
WRITE_DATASOURCEprivilege for a particular graph user may create a local data source for that graph:
GSQL > CREATE DATA_SOURCE KAFKA k1 = "/path/to/config" FOR GRAPH test_graph|
In the above statement, the local data_source k1 is only accessible to graph test_graph. A superuser cannot grant it to another graph. |
DROP DATA_SOURCE
A data source variable can be dropped by a user who has sufficient privileges.
A global data source can only be dropped by a users with global WRITE_DATASOURCE privilege.
Users with WRITE_DATASOURCE privilege for one graph can drop data sources on that graph.
The syntax for the DROP DATA_SOURCE command is as follows:
GSQL > DROP DATA_SOURCE <source1>[<source2>...] | * | ALLBelow are several examples of Kafka data source CREATE and DROP commands.
GSQL > CREATE DATA_SOURCE KAFKA k1 = "/home/tigergraph/kafka.conf"
GSQL > CREATE DATA_SOURCE KAFKA k2 = "/home/tigergraph/kafka2.conf"
GSQL > DROP DATA_SOURCE k1, k2
GSQL > DROP DATA_SOURCE *
GSQL > DROP DATA_SOURCE ALLSHOW DATA_SOURCE
The SHOW DATA_SOURCE command will display a summary of all existing data sources for which the user has privilege:
GSQL > SHOW DATA_SOURCE *
# the sample output
Data Source:
- KAFKA k1 ("127.0.0.1:9092")
The global data source will be shown in global scope. The graph scope will only show the data source it has access to.Manage loading jobs
Kafka Loader loading jobs are managed the same way as regular loading jobs. The three key commands are
-
SHOW LOADING STATUS -
ABORT LOADING JOB -
RESUME LOADING JOB
For example, the syntax for the SHOW LOADING STATUS command is as follows:
SHOW LOADING STATUS job_id|ALLTo refer to a specific job instance, using the job_id which is provided when RUN LOADING JOB is executed. For each loading job, the above command reports the following information :
-
Current loaded offset for each partition
-
Average loading speed
-
Loaded size
-
Duration
See Inspecting and Managing Loading Jobs for more details.