Kafka Loader Overview
Kafka is a popular pub-sub system in enterprise IT, offering a distributed and fault-tolerant real-time data pipeline. The Kafka Loader lets you integrate TigerGraph with a Kafka cluster and speed up your real-time data ingestion. The Kafka Loader is easily extensible using the many plugins available in the Kafka ecosystem.
The Kafka Loader consumes data in a Kafka cluster and loads data into the TigerGraph system. Multiple loading jobs created with the Kafka Loader can run at the same time to stream data from various sources into the TigerGraph system concurrently.
Architecture
From a high level, a user provides instructions to the TigerGraph system through GSQL, and the external Kafka cluster loads data into TigerGraph’s RESTPP server. The following diagram demonstrates the Kafka Loader data architecture.
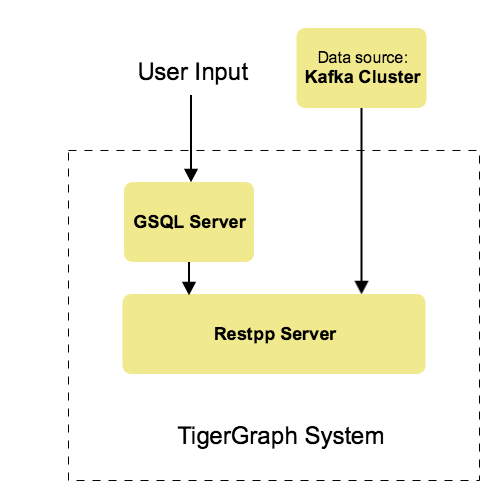
|
The Kafka loader doesn’t use consumer groups, and therefore doesn’t support HA. If a loading job is interrupted, you need to manually resume the loading job. A resumed job picks up from where it was stopped before and will not consume messages that have already been consumed. |