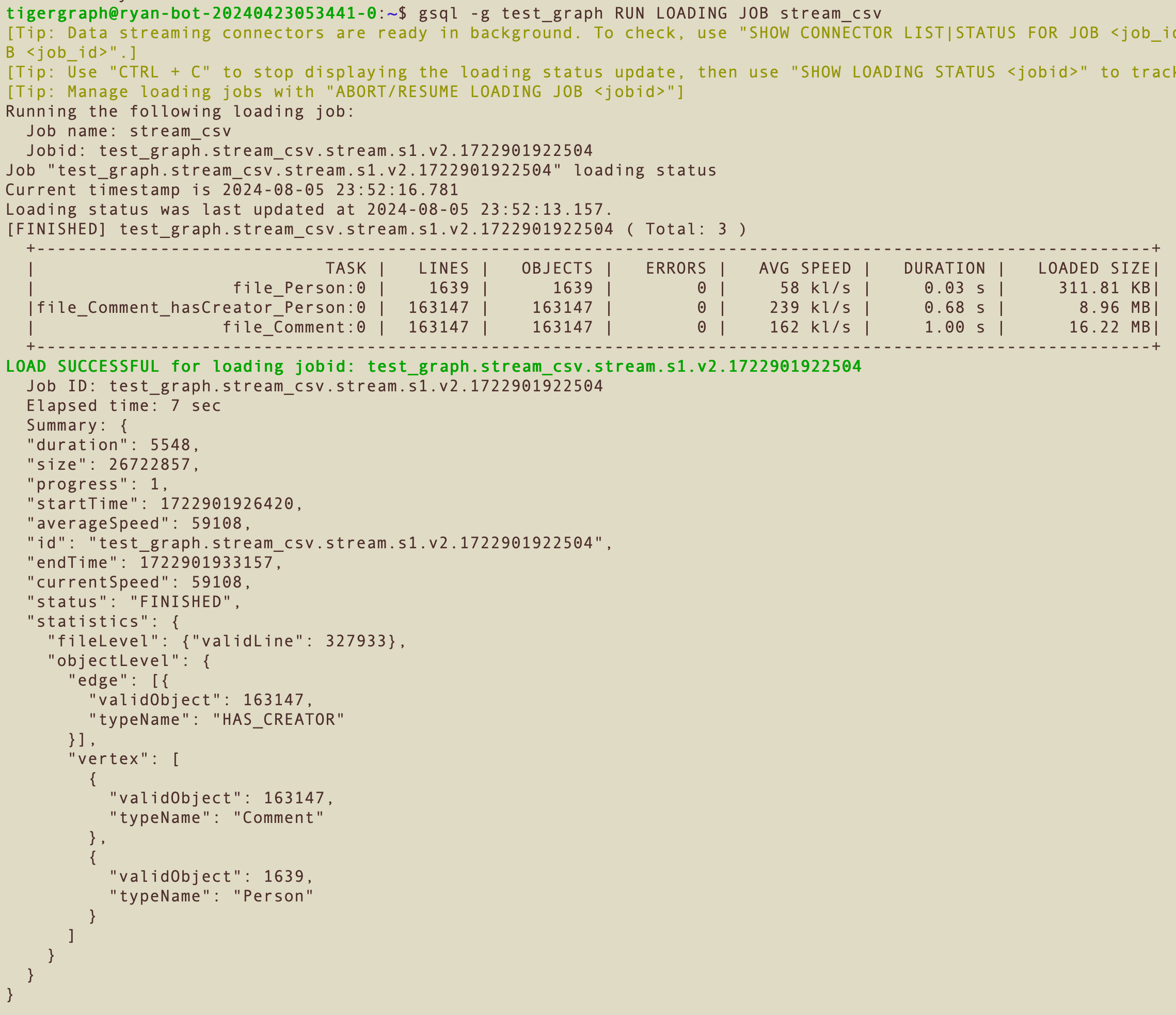
Data Loading HA
When the TigerGraph database is configured with HA replicas, then data loading automatically takes advantage of the replicas to provide improved loading speed, reduced disk usage, load balancing, and automatic failover, at no additional system resource costs.
This ensures continuous data loading operations even in the event of a single-node disruption, making it especially valuable for critical applications requiring consistent data availability.
HA is not designed to provide continuous operation across configuration changes. For example, if Nginsx SSL security is reconfigured while a loading job is running, the loading job will fail.
Disabling and Reenabling Data Loading HA
Data loading with HA was introduced in TigerGraph 4.1 as an option called Data Loading V2, enabled by setting the configuration parameter KafkaConnect.EnableV2 to true.
As of 4.2, this parameter defaults to true. If for some reason you wish to disable this model, you can do so by setting the parameter to false and then applying the new server settings.
gadmin config set KafkaConnect.EnableV2 false
gadmin config apply --restart-depsYou would reenable Data Loading HA by setting it to true again and running gadmin config apply.
|
Do not run loading jobs while changing enabling or disabling the HA mode. |