Load from Amazon S3
If you store your data in Amazon S3, TigerGraph Savanna provides seamless integration for data ingestion. You can directly load data from your S3 buckets into your graph databases, eliminating the need for manual data transfers. This simplifies the process of importing large datasets and enables you to leverage the scalability and durability of Amazon S3 for your graph analysis.
1) Select Source
Once you’ve selected Amazon S3, you will be asked to configure the Amazon S3 data source.
-
Click on
 to add a new Amazon S3 data source.
to add a new Amazon S3 data source.
-
You will need to provide your S3
AWS access key idand S3AWS secret access key.
-
Once you have those configured, you can add one or multiple
S3 URIwithin the same S3 bucket. -
Click Next to process the file(s).
The current data loading tool only supports CSV,TSV and JSON files. Other formats will be available in later releases.
2) Configure File
This step lets you configure the source file details.
-
The data loading tool will automatically detect the
.csvseparators and line breaks. The parser automatically splits each line into a series of tokens.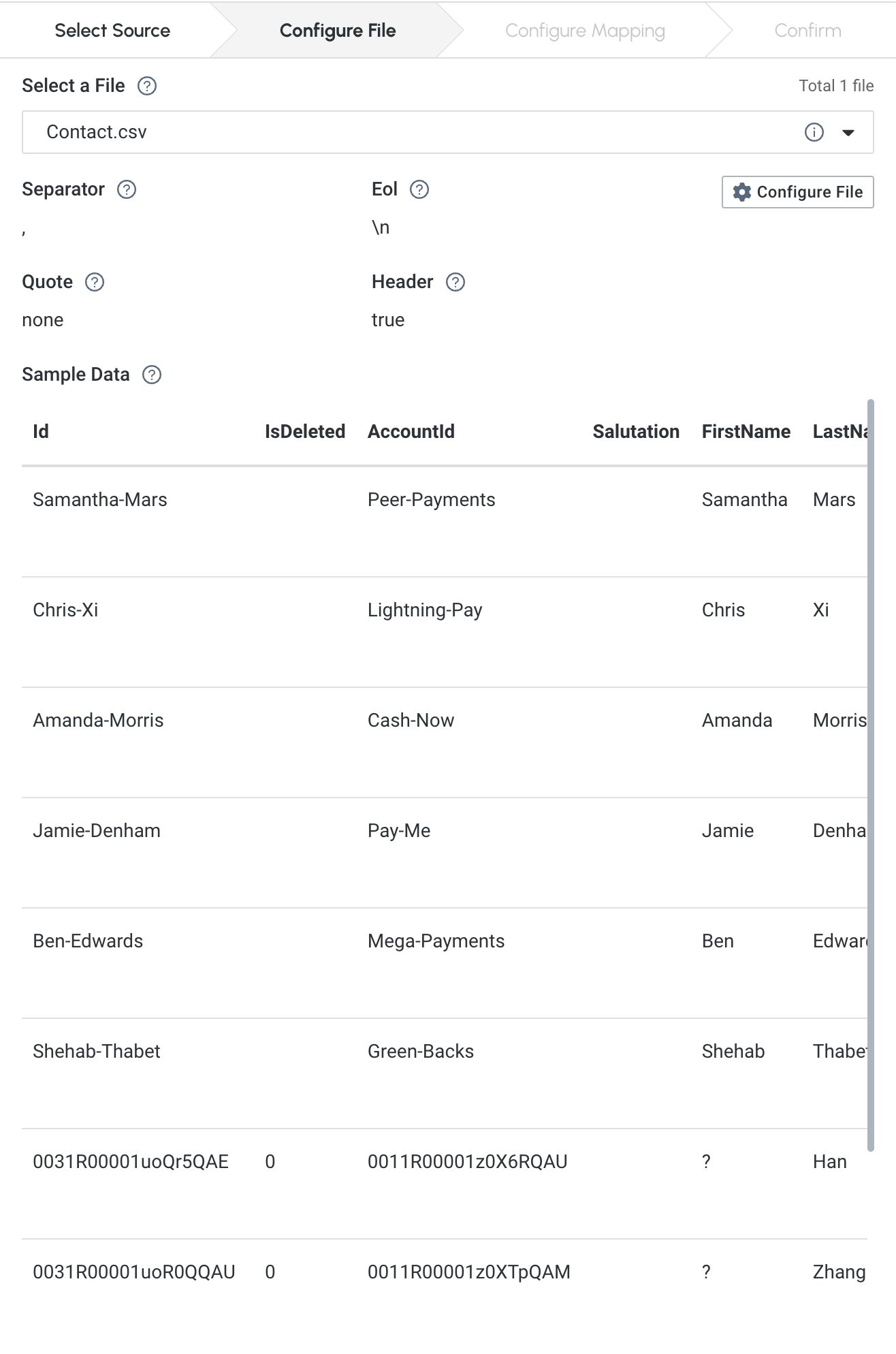
If the parsing is not correct, click on the
 button to configure a different option for the delimiter, such as
button to configure a different option for the delimiter, such as eol, orquote and header.
The enclosing character is used to mark the boundaries of a token, overriding the delimiter character.
For example, if your delimiter is a comma, but you have commas in some strings, then you can define single or double quotes as the enclosing character to mark the endpoints of your string tokens.
It is not necessary for every token to have enclosing characters. The parser uses enclosing characters when it encounters them.
You can edit the header line of the parsing result to give each column a more intuitive name, since you will be referring to these names when loading data to the graph. The header name is ignored during data loading.
-
Once you are satisfied with the file settings, click Next to proceed.
3) Configure Map
If you are loading data into a brand new graph, you will be prompted to let our engine generate a schema and mapping for you. Or you can start from scratch. For more details of schema design please refer to Design Schema.
-
Select
Generate the schema onlyorGenerate the schema and data mapping.
The schema generation feature is still a preview feature. The correctness and efficiency of the resulting graph schema and mapping could vary.
-
In the
Sourcecolumn, you can choose the specific column from the data source that you want to map with the attribute.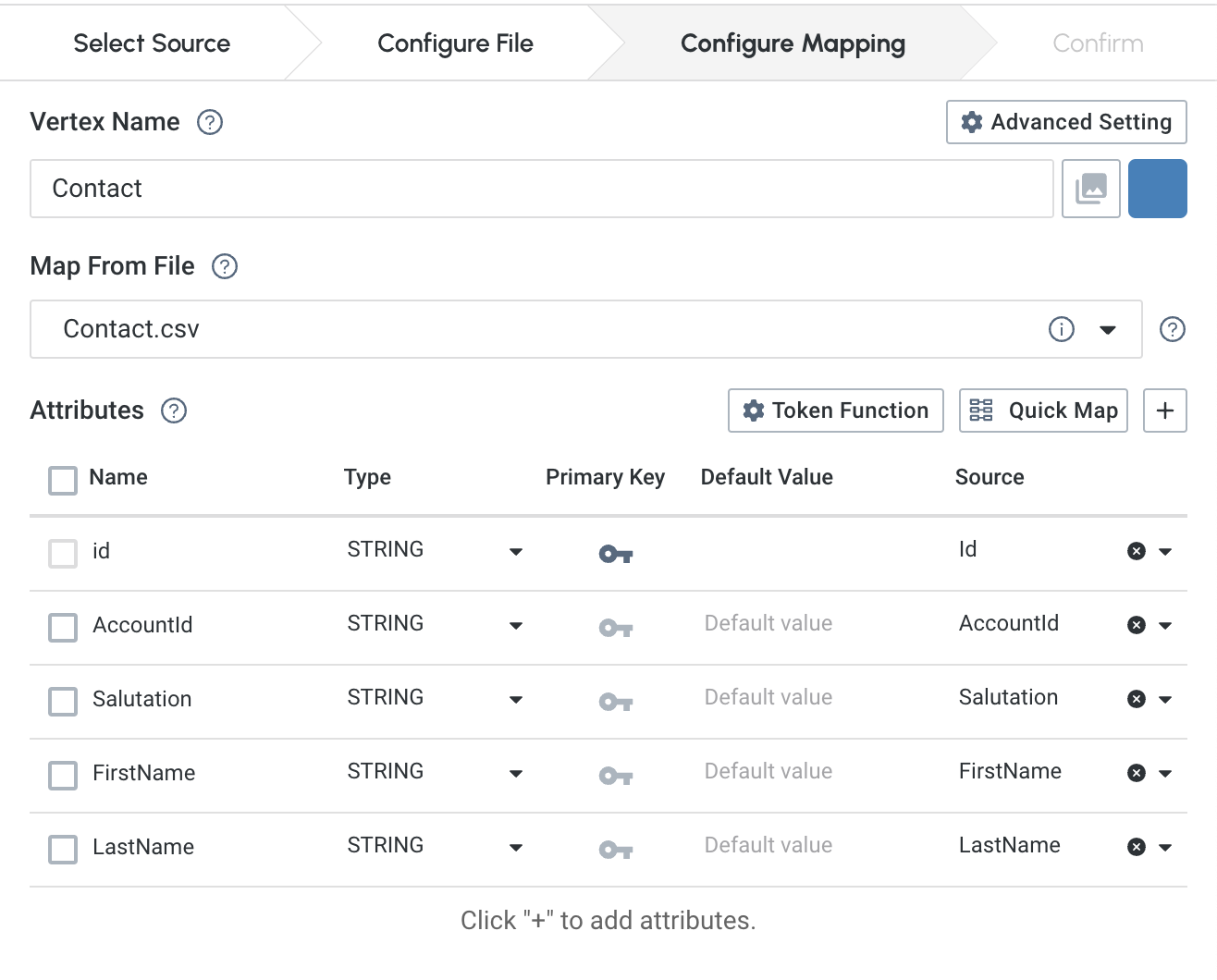
-
Use the
+button to create a new attribute of the target vertex or edge.
-
Click the Token Function button to configure token functions for the selected source. For more details of configuring token functions, please refer to Token Function.
-
Click the Quick Map button to quickly map the data source headers to the existing schema attributes.
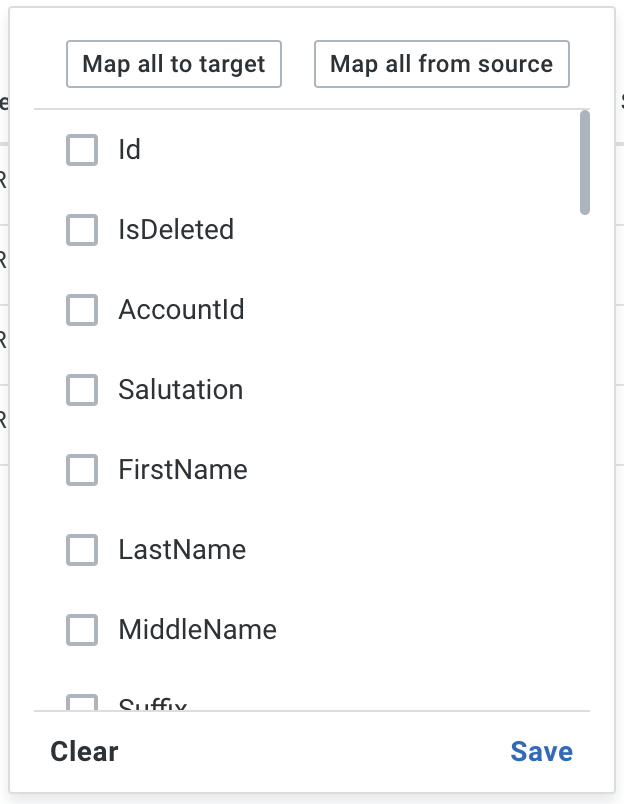
-
The Map all to target button aligns existing attribute names with the corresponding data source headers, it won’t introduce new attributes.
-
The Map all from source button not only aligns existing attribute names with the corresponding data asource headers, but also introduces new attributes based on unmatched data source headers.
-
The following list shows the mapping status of each attribute. You can manually adjust the mapping by checking the box next to the attribute name.
-
-
Click Next to proceed.
4) Confirm
This step will let you confirm the changes made to the schema and the data mapping you created to load the data.
-
Simply review the
Schema to be changedandData to be loadedlists.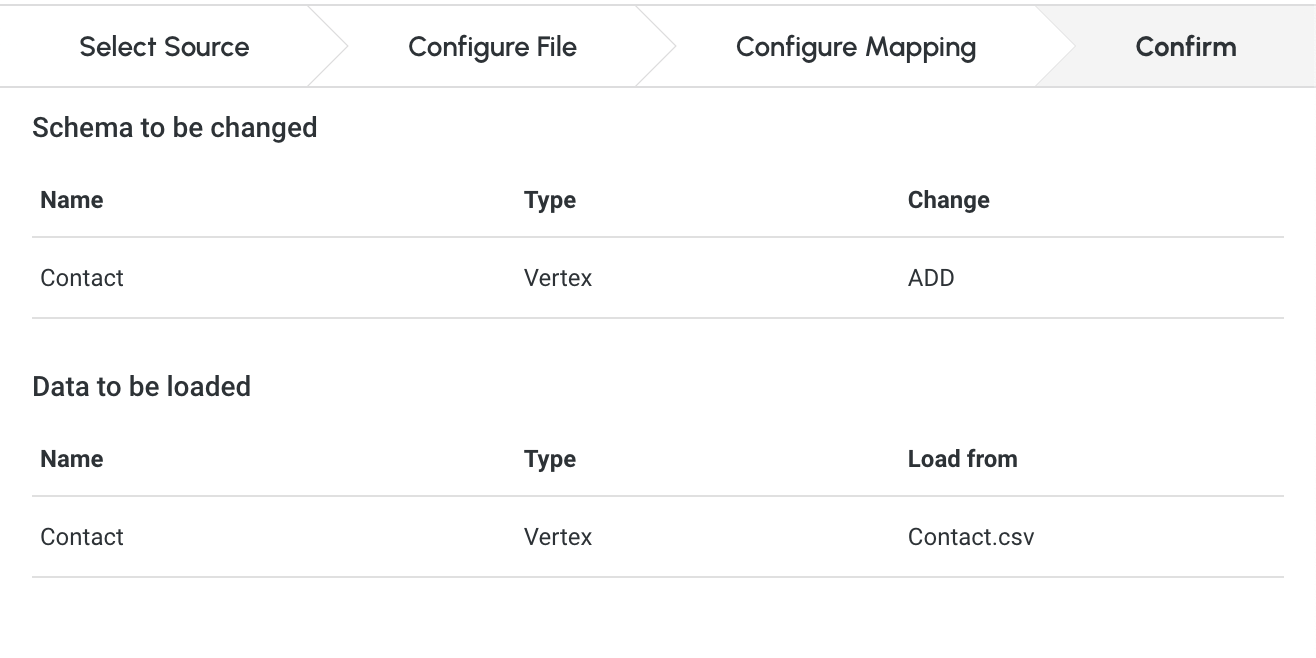
Please be aware that some schema changes will result in unintentional deletion of the data. Please carefully review the warning message before confirming the loading.
-
Click on the Confirm button to run the loading jobs and monitor their
Status.
Next Steps
Next, learn how to use Design Schema, GSQL Editor and Explore Graph in TigerGraph Savanna.
Or return to the Overview page for a different topic.