High Availability Cluster Configuration
TigerGraph HA service provides load balancing when all components are operational, as well as automatic failover in the event of a service disruption.
The following terms describe the size and dimension of a HA cluster:
- replication factor
-
Total number of instances of your data. Each instance of data may be partitioned across multiple machines.
- partitioning factor
-
Number of machines across which one copy of the data is distributed. In practice, the partitioning factor of a cluster is decided by dividing the total number of machines in the cluster by the replication factor.
- cluster size
-
Total number of machines in the cluster.
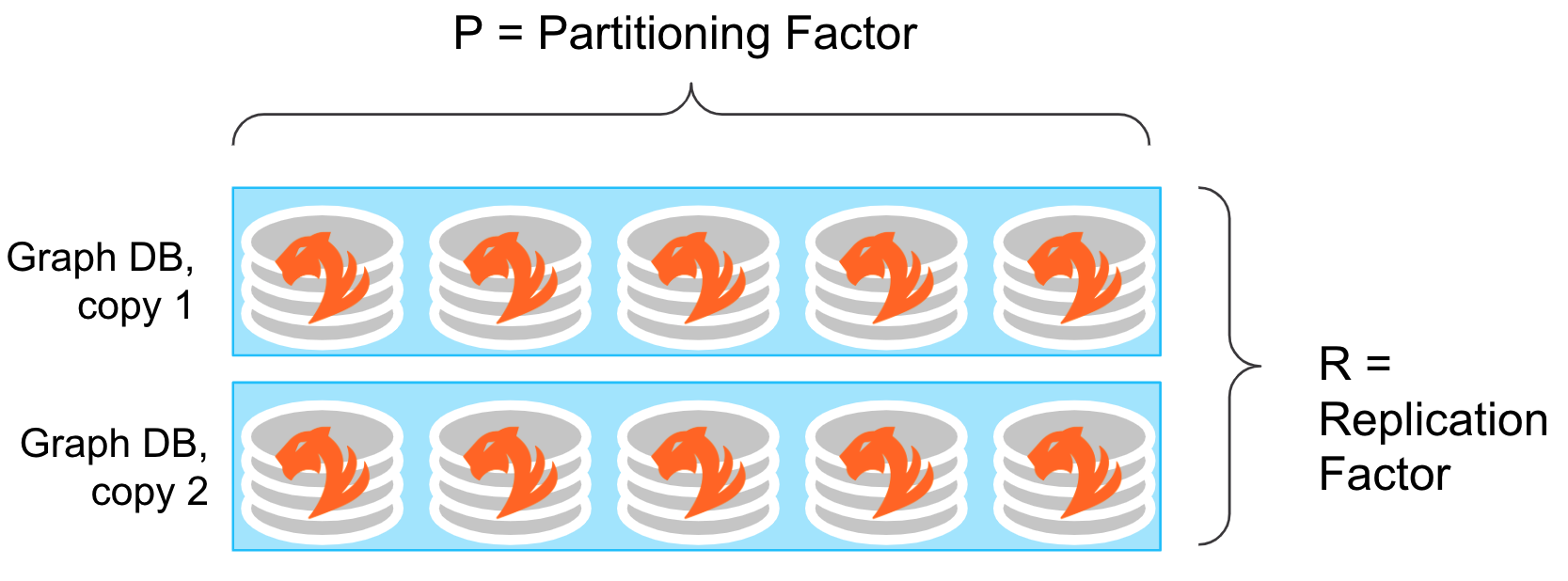
If an HA cluster has both a replication factor of 2 and a partitioning factor of 3, the cluster has a total of six machines. With the six machines, the cluster maintains two instances of the data, each distributed across three machines.
Replication and distribution both increase query throughput and improve system resiliency. There is no upper limit for either partitioning factor or replication factor.
For example, the following cluster has a replication factor of 2 and a cluster size of 10, which produces a partitioning factor of \(10 / 2 = 5\).
System Requirements (Minimal Configurations)
-
To enable HA, the minimum replication factor is 2.
-
HA also requires a minimum cluster size of 3, so the absolute smallest HA cluster would be 1x3 (a single-server database with 3 instances).
-
The smallest HA cluster using partitioning would be 2x2.
-
If you choose to resize a cluster after installation, ensure every node across the cluster is running the same version of TigerGraph.
Configuring HA settings
There are two ways of configuring HA settings for a cluster:
-
Configure HA settings during installation.
-
Expand or Shrink a Cluster after installation.
Configure HA settings during installation
Configuring a HA cluster is part of platform installation.
During TigerGraph platform installation, specify the replication factor. The default value for replication factor is 1, which means high availability is not set up for the cluster.
You do not explicitly set the partitioning factor. Instead, the TigerGraph system will set the partitioning factor through the following formula:
partitioning factor = (number of machines / replication factor)
If the division does not produce an integer, some machines will be left unused. For example, if you install a 7-node cluster with a replication factor of 2, the resulting configuration is 2-way HA for a database with a partitioning factor of 3. One machine is left unused.
Resize a running cluster
In addition to configuring HA settings during installation, you can also resize a running cluster.
Cluster resizing allows you to perform the following:
During cluster resizing, you should expect a brief amount of cluster downtime, during which your cluster will not be able to respond to requests. The specific amount of downtime varies depending on your cluster size, machine memory and CPU, etc. For reference:
| Before expansion | After expansion | |
|---|---|---|
Replication factor |
2 |
2 |
Partitioning factor |
2 |
4 |
Data volume (per copy) |
100 GB |
|
Instance type |
GCP EC2 with 8 vCPUs and 32 GB memory |
|
Downtime |
About 4 minutes |
|
| Before expansion | After expansion | |
|---|---|---|
Replication factor |
2 |
4 |
Partitioning factor |
4 |
4 |
Data volume (per copy) |
500 GB |
|
Instance type |
GCP EC2 with 8 vCPUs and 32 GB memory |
|
Downtime |
About 9 minutes |
|
Configure bucket number to reduce data skew
When you set up an HA cluster, TigerGraph automatically distributes data across different partitions in buckets for every instance of your data. The default number of buckets is fixed and does not change based on the number of partitions. When the number of buckets cannot be evenly divided by the number of partitions, more data is distributed to the partitions with extra buckets, resulting in data skew. However, you can configure the number of buckets before data loading to reduce or avoid data skew.
The number of buckets is controlled by the parameter GPE.NumberOfHashBucketInBit.
The number of buckets equals 2 to the power of the value of the parameter GPE.NumberOfHashBucketInBit.
The default value of GPE.NumberOfHashBucketInBit is 5.
Therefore, a cluster has \(2^5 = 32\) buckets by default.
This means that data skew happens when you have a partition number that cannot evenly divide 32. Data skew is more significant when the modulus \(M = N_{bucket} \bmod N_{partition}\) is closer to half of \(N_{partition}\), where \(N_{bucket}\) is the number of buckets, and \(N_{partition}\) is the number of partitions.
To minimize data skew as well as resource contention issues that can be caused by a high number of buckets, choose a low bucket number that leaves the modulus close to either 0 or the number of partitions.
| We do not suggest you adjust the bucket number to be lower than the default value. A bucket number that is too low might negatively impact performance. |
Example
For example, if each instance of your data has 9 partitions, the 32 buckets are distributed as follows:
| Partition | Buckets | |||
|---|---|---|---|---|
Partition #1 |
Bucket #1 |
Bucket #10 |
Bucket #19 |
Bucket #28 |
Partition #2 |
Bucket #2 |
Bucket #11 |
Bucket #20 |
Bucket #29 |
Partition #3 |
Bucket #3 |
Bucket #12 |
Bucket #21 |
Bucket #30 |
Partition #4 |
Bucket #4 |
Bucket #13 |
Bucket #22 |
Bucket #31 |
Partition #5 |
Bucket #5 |
Bucket #14 |
Bucket #23 |
Bucket #32 |
Partition #6 |
Bucket #6 |
Bucket #15 |
Bucket #24 |
|
Partition #7 |
Bucket #7 |
Bucket #16 |
Bucket #25 |
|
Partition #8 |
Bucket #8 |
Bucket #17 |
Bucket #26 |
|
Partition #9 |
Bucket #9 |
Bucket #18 |
Bucket #27 |
|
Partitions #1 to #5 each have 4 buckets, while partitions #6 to #9 only have 3 buckets. This means that each partition between #1 to #5 has 33% more data than a partition between #6 and #9. Therefore, partitions #1 to #5 altogether end up storing 20 / 32 = 62.5% percent of the data, when they should only store 5 / 9 = 55.5%.
To reduce data skew in this scenario, the number of partitions should divide more evenly into the number of buckets.
Change GPE.NumberOfHashBucketInBit to 6 by running the following command:
$ gadmin config set GPE.NumberOfHashBucketInBit 6This leaves the cluster with \(2^6=64\) buckets. Each partition has 7 buckets, and only partition 1 has one extra bucket.