Data Loading V2 (BETA)
| This is currently a beta feature |
Data Loading V2 is the latest data loading technology which provides improved loading speed, reduced disk usage, and support for high availability (HA) at no additional system resource costs.
Data Loading high availability (HA) is supported by default when data loading V2 is enabled. Data Loading HA enhances the reliability and efficiency of data loading processes by providing load balancing and automatic failover. This ensures continuous data loading operations even in the event of a service disruption, making it especially valuable for critical applications requiring consistent data availability.
Setup
To enable data loading V2, simply enable Kafka Connect V2 using gadmin commands.
gadmin config set KafkaConnect.EnableV2 trueThen run config apply to restart dependency services.
gadmin config apply --restart-depsHA Setup
To enable data loading HA, use a cluster with replication factor greater than 1 following High Availability Cluster Configuration.
Then data loading HA will be enabled by default with data loading V2 enabled.
Validation
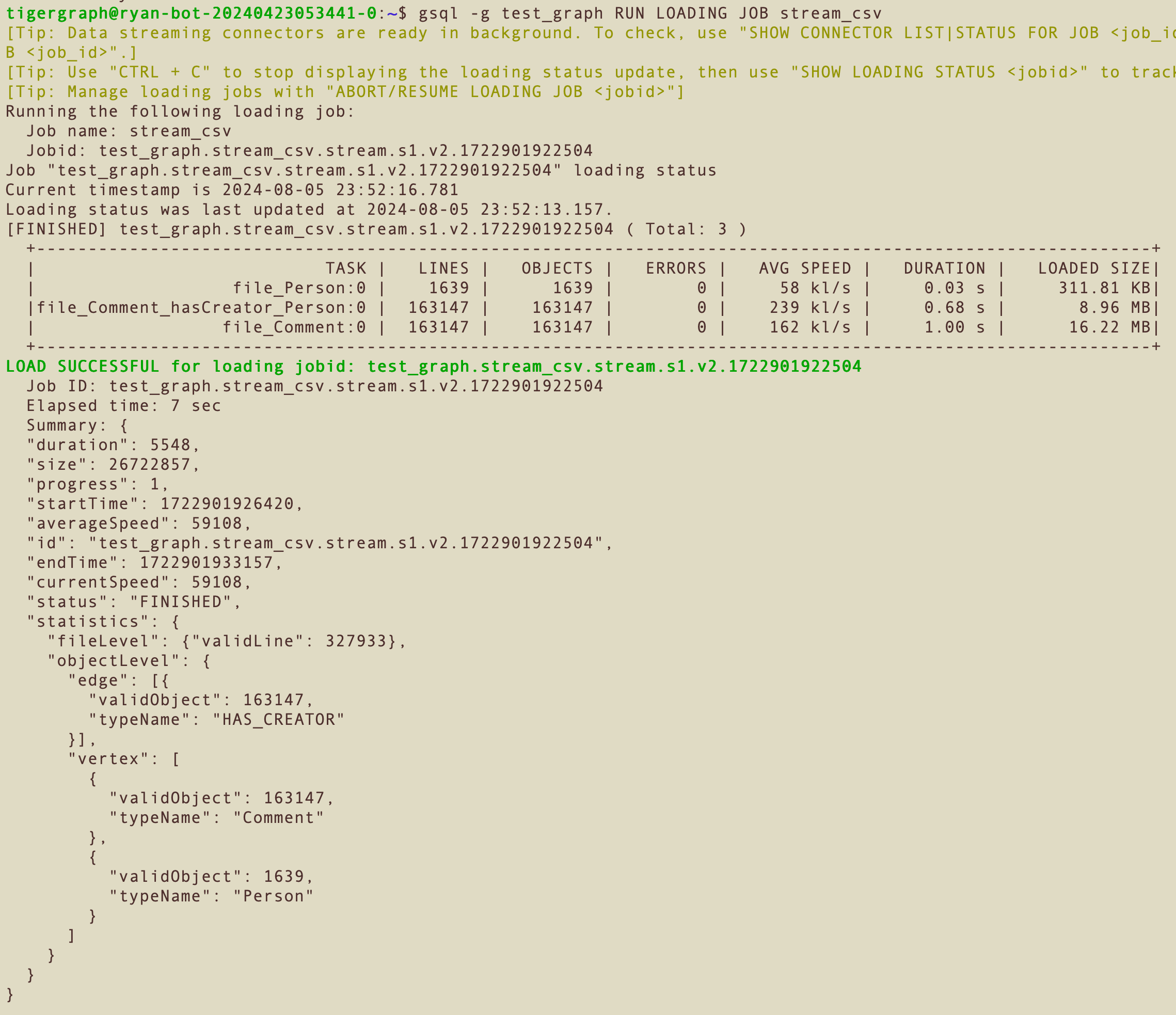
To confirm data loading V2 is successfully enabled, try running a loading job as usual described in Data Loading Overview.
The jobid generated for the loading job should contain v2, for example, test-graph.stream_csv.stream.s1.v2.1722901922504.
The loading status will also be shown in slightly different format from V1.
If you want to validate the HA capability, you may shut down one node or service in the TigerGraph cluster. The data loading process should automatically adjust and continue.
Run Loading Job
You can now run any loading job as usual following these instructions Data Loading Overview.
Configuration
| Key | Default Value | Description | Note |
|---|---|---|---|
|
0 (infinite) |
The data size to be broken into if data in batch.size.rows is larger than batch.size.bytes. Example, each row of data is 1kb, and batch.size.rows = 10, batch.size.bytes = 5000, the data will be split into 2 5kb batches. Example usage: |
Only takes effect if data loading V2 is enabled |
| Modifying security configs such as Nginx SSL while loading job is running may cause the loading job to fail. |