SELECT Statement (Syntax V1)
This page describes the GSQL SELECT statement in GSQL Syntax V1.
The default syntax is syntax v2.
To use syntax v1, you need to declare the syntax at the query level or in a session parameter.
The SELECT block uses a step pattern to select some of the graph’s vertices and edges. There are a number of optional clauses that define and/or refine the selection by constraining the vertex or edge set or the result set. The final output of a query is either a vertex set known as the result set or a table.
|
Size limitation There is a maximum size limit of 2 GB for the result set of a SELECT block . If the result of the SELECT block is larger than 2 GB, the system will return no data. NO error message is produced. |
gsqlSelectBlock := gsqlSelectClause
fromClause
[sampleClause]
[whereClause]
[accumClause]
[postAccumClause]*
[havingClause]
[orderClause]
[limitClause]
gsqlSelectClause := vertexSetName "=" SELECT vertexAliasIn classic GSQL, the SELECT statement is an assignment statement with a SELECT block on the right-hand side. The initial clause is the SELECT clause: SELECT vertexAlias. Its purpose is to specify which set of vertices from the FROM clause is to become the output. The classic SELECT clause may contain only one item: a vertex alias defined in the FROM clause. As of v3.1, the vertex alias may be from anywhere in a multi-hop pattern, not only an endpoint. GSQL now also supports SQL-like SELECT statements with tabular output.
The FROM defines a path pattern to traverse in the graph, and each vertex in the path pattern can be given a vertexAlias name. Thus, the SELECT clause picks the set of vertices at one of these points in the pattern — the source vertices, the target vertices, or those from an interior point in a multi-hop path — to be the output vertices.
The SELECT block has many optional clauses, which fit together in a logical flow. Overall, the SELECT block starts from a source set of vertices and returns a result set that is either a subset of the source vertices or a subset of their neighboring vertices. Along the way, computations can be performed on the selected vertices and edges. The figure below graphically depicts the overall SELECT data flow. While the ACCUM and POST-ACCUM clauses do not directly affect which vertices are included in the result set, they affect the data (accumulators) which are attached to those vertices.
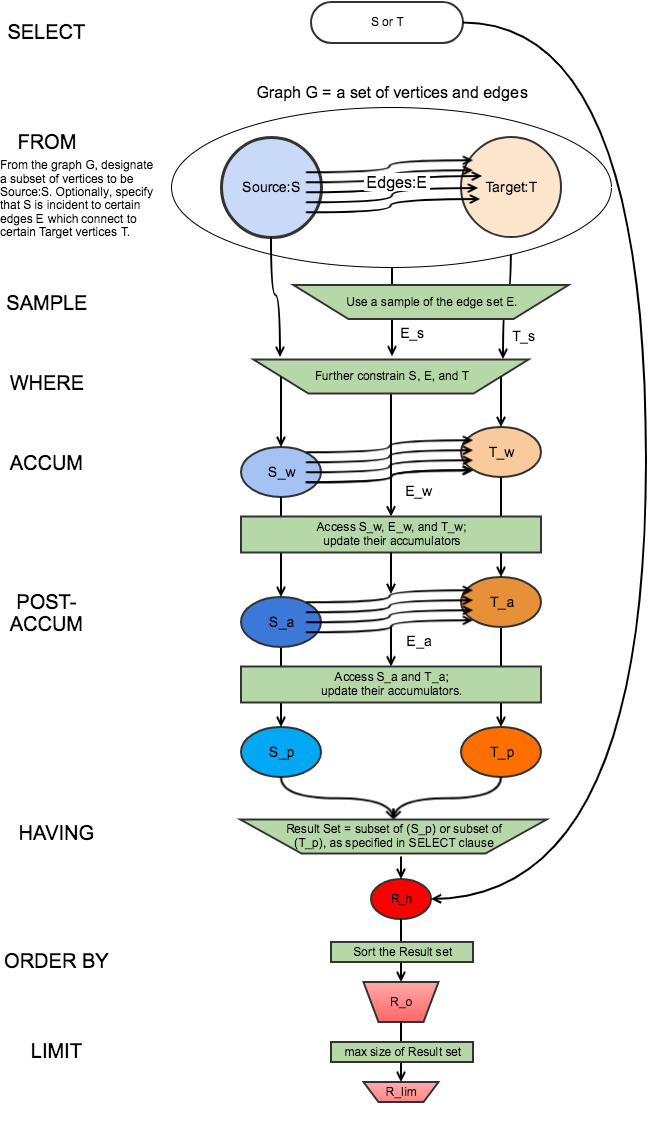
FROM
In classic (Syntax v1) GSQL, the FROM clause describes one step or hop pattern.
fromClause := FROM (step | stepV2 | pathPattern ["," pathPattern]*)A hop or step consists of going from a starting set of vertices, crossing over a set of their edges, to an ending set of vertices.
We typically use the names Source and Target for the starting and ending vertex sets: Source -(Edges)-> Target
The step pattern defines constraints for the Source set, the Edge set, and the Target set. The result of the FROM clause can be interpreted as a 3-column virtual table called the match table. Each row is a 3-element tuple: (source vertex, connected edge, target vertex).
Source Vertex Set (SYNTAX v1)
Notice that the edge set and target set are optional: a step can be just source vertices (stepSourceSet).
step := stepSourceSet ["-" "(" stepEdgeSet ")" ("-"|"->") stepVertexSet]|
Rules for Source Vertex Set in Syntax V1:
|
For example:
resultSet = SELECT s FROM Source:s;This statement can be interpreted as "Select all vertices s, from the vertex set Source ." The result is a vertex set. Below is a simple example of a vertex selection.
# displays all 'post'-type vertices
CREATE QUERY printAllPosts() FOR GRAPH socialNet SYNTAX V1
{
start = {post.*}; # initialized with all vertices of type 'post'
results = SELECT s FROM start:s; # select these vertices
PRINT results;
}GSQL > RUN QUERY printAllPosts()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"results": [
{
"v_id": "0",
"attributes": {
"postTime": "2010-01-12 11:22:05",
"subject": "Graphs"
},
"v_type": "post"
},
{
"v_id": "10",
"attributes": {
"postTime": "2011-02-04 03:02:31",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "2",
"attributes": {
"postTime": "2011-02-03 01:02:42",
"subject": "query languages"
},
"v_type": "post"
},
{
"v_id": "4",
"attributes": {
"postTime": "2011-02-07 05:02:51",
"subject": "coffee"
},
"v_type": "post"
},
{
"v_id": "9",
"attributes": {
"postTime": "2011-02-05 23:12:42",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "3",
"attributes": {
"postTime": "2011-02-05 01:02:44",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "5",
"attributes": {
"postTime": "2011-02-06 01:02:02",
"subject": "tigergraph"
},
"v_type": "post"
},
{
"v_id": "7",
"attributes": {
"postTime": "2011-02-04 17:02:41",
"subject": "Graphs"
},
"v_type": "post"
},
{
"v_id": "1",
"attributes": {
"postTime": "2011-03-03 23:02:00",
"subject": "tigergraph"
},
"v_type": "post"
},
{
"v_id": "11",
"attributes": {
"postTime": "2011-02-03 01:02:21",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "8",
"attributes": {
"postTime": "2011-02-03 17:05:52",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "6",
"attributes": {
"postTime": "2011-02-05 02:02:05",
"subject": "tigergraph"
},
"v_type": "post"
}
]}]
}1-Hop Step (SYNTAX v1)
Usually, a FROM clause has a full 1-hop step.
step := stepSourceSet ["-" "(" stepEdgeSet ")" ("-"|"->") stepVertexSet]The symbols -( and )- enclose the stepEdgeSet and separate the three parts. Each of the three parts may also define an alias, which makes a convenient way to refer to each of the three sets of entities.
stepSourceSet := vertexSetName [":" vertexAlias]
stepEdgeSet := [setEdgeTypes] [":" edgeAlias]
stepVertexSet := [setVertexTypes] [":" vertexAlias]Below is a simple example:
Person:s -( (Bought|Rented):e )- (Product|Service):tThe Source set is all Persons, but the pattern will not include all Persons. It will only include those Persons who Bought or Rented a Product or Service. Moreover, the result will be a set of matched triples: (s, e, t). For example, if Sam bought a TV and Andy rented a car, the results will include (Sam, Bought, TV) and (Andy, Rented, Car). However, these two facts do not imply (Sam, Rented, Car) or (Andy, Rented, TV).
|
The GSQL grammar allows the right-hand enclosure to be either |
Edge Set and Target Vertex Set Options
|
Rules for Edge Set and Target Set in Syntax V1:
|
| Notation | Accepted vertex/edge types |
|---|---|
(empty) |
any type |
_ |
any type |
ANY |
any type |
vertex/edge type name |
given type |
string parameter holding a vertex/edge type name |
given type |
global SetAccum containing vertices or edges |
given set |
(name | name …) |
UNION of two or more collections |
|
Parentheses are always needed around the edge type in a FROM clause: Parentheses are also needed if a vertexEdgeType is the union of more than one or more individual edge types or vertex types: Note the double set of parentheses for the edge specifier.
If there is an edge alias, these parentheses are needed.
If however there is no edge alias, it is legal to have just a single set of parentheses: |
Either the source vertex set ( s ) or target vertex set ( t ) can be used as the SELECT argument, which determines the result of the SELECT statement. Note the small difference in the two SELECT statements below.
resultSet1 = SELECT s FROM source:s-(eType:e)-tType:t; //select from the source set
resultSet2 = SELECT t FROM source:s-(eType:e)-tType:t; //select from the target setresultSet1 is based on the source end of the edges. resultSet2 is based on the target end of the selected edges. However, resultSet1 is NOT identical to the Source vertex set. It is only those members of Source which connect to an eType edge and then to a tType vertex. Other clauses (presented later in this "SELECT Statement" section, can do additional filtering of the Source set.
|
We strongly suggest that an alias should be declared with every vertex and edge in the FROM clause, as there are several functions and features which are only available to vertex and edge aliases. |
It is legal to declare an alias without explicitly stating an edge/target type. See the examples below.
resultSet3 = SELECT v FROM Source:v-(eType:e)-(V1|V2):t;
resultSet4 = SELECT v FROM Source:v-(eType:e)-:t;
resultSet5 = SELECT v FROM Source:v-(eType:e)-ANY:t;
resultSet6 = SELECT v FROM Source:v-(eType:e)-_:t;resultSet7 = SELECT v FROM Source:v-((E1|E2|E3):e)-tType:t;
resultSet8 = SELECT v FROM Source:v-(:e)-tType:t;
resultSet9 = SELECT v FROM Source:v-(_:e)-tType:t;
resultSet10 = SELECT v FROM Source:v-(ANY:e)-tType:t;The following are a set of queries that demonstrate edge-induced SELECT blocks. The allPostsLiked and allPostsMade queries show how the target vertex type can be omitted. The allPostsLikedOrMade query uses the "|" operator to select multiple types of edges.
# uses various SELECT statements (some of which are equivalent) to print out
# either the posts made by the given user, the posts liked by the given
# user, or the posts made or liked by the given user.
CREATE QUERY printAllPosts2(vertex<person> seed) FOR GRAPH socialNet SYNTAX V1
{
start = {seed}; # initialize starting set of vertices
# --- statements produce equivalent results
# select all 'post' vertices which can be reached from 'start' in one hop
# using an edge of type 'liked'
allPostsLiked = SELECT targetVertex FROM start -(liked:e)- post:targetVertex;
# select all vertices of any type which can be reached from 'start' in one hop
# using an edge of type 'liked'
allPostsLiked = SELECT targetVertex FROM start -(liked:e)- :targetVertex;
# ----
# --- statements produce equivalent results
# start with the vertex set from above, and traverse all edges of type "posted"
# (locally those edges are just given a name 'e' in case they need accessed)
# and return all vertices of type 'post' which can be reached within one-hop of 'start' vertices
allPostsMade = SELECT targetVertex FROM start -(posted:e)- post:targetVertex;
# start with the vertex set from above, and traverse all edges of type "posted"
# (locally those edges are just given a name 'e' in case they need accessed)
# and return all vertices of any type which can be reached within one-hop of 'start' vertices
allPostsMade = SELECT targetVertex FROM start -(posted:e)- :targetVertex;
# ----
# --- statements produce equivalent results
# select all vertices of type 'post' which can be reached from 'start' in one hop
# using an edge of any type
# not equivalent to any statement. because it doesn't restrict the edge type,
# this will include any vertex connected by 'liked' or 'posted' edge types
allPostsLikedOrMade = SELECT t FROM start -(:e)- t;
# select all vertices of type 'post' which can be reached from 'start' in one hop
# using an edge of type either 'posted' or 'liked'
allPostsLikedOrMade = SELECT t FROM start -((posted|liked):e)- post:t;
# select all vertices of any type which can be reached from 'start' in one hop
# using an edge of type either 'posted' or 'liked/
allPostsLikedOrMade = SELECT t FROM start -((posted|liked):e)- :t;
#option for simplified parentheses in edge pattern:
allPostsLikedOrMade = SELECT t FROM start - (posted|liked)- :t
# ----
PRINT allPostsLiked;
PRINT allPostsMade;
PRINT allPostsLikedOrMade;
}GSQL > RUN QUERY printAllPosts2("person2")
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [
{"allPostsLiked": [
{
"v_id": "0",
"attributes": {
"postTime": "2010-01-12 11:22:05",
"subject": "Graphs"
},
"v_type": "post"
},
{
"v_id": "3",
"attributes": {
"postTime": "2011-02-05 01:02:44",
"subject": "cats"
},
"v_type": "post"
}
]},
{"allPostsMade": [{
"v_id": "1",
"attributes": {
"postTime": "2011-03-03 23:02:00",
"subject": "tigergraph"
},
"v_type": "post"
}]},
{"allPostsLikedOrMade": [
{
"v_id": "0",
"attributes": {
"postTime": "2010-01-12 11:22:05",
"subject": "Graphs"
},
"v_type": "post"
},
{
"v_id": "3",
"attributes": {
"postTime": "2011-02-05 01:02:44",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "1",
"attributes": {
"postTime": "2011-03-03 23:02:00",
"subject": "tigergraph"
},
"v_type": "post"
}
]}
]
}
GSQL > RUN QUERY printAllPosts2("person6")
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [
{"allPostsLiked": [{
"v_id": "8",
"attributes": {
"postTime": "2011-02-03 17:05:52",
"subject": "cats"
},
"v_type": "post"
}]},
{"allPostsMade": [
{
"v_id": "10",
"attributes": {
"postTime": "2011-02-04 03:02:31",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "5",
"attributes": {
"postTime": "2011-02-06 01:02:02",
"subject": "tigergraph"
},
"v_type": "post"
}
]},
{"allPostsLikedOrMade": [
{
"v_id": "10",
"attributes": {
"postTime": "2011-02-04 03:02:31",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "5",
"attributes": {
"postTime": "2011-02-06 01:02:02",
"subject": "tigergraph"
},
"v_type": "post"
},
{
"v_id": "8",
"attributes": {
"postTime": "2011-02-03 17:05:52",
"subject": "cats"
},
"v_type": "post"
}
]}
]
}This example is another edge selection that uses the "|" operator to select edges that have target vertices of multiple types.
# uses a SELECT statement to print out everything related to a given user
# this includes posts that the user liked, posts that the user made, and friends
# of the user
CREATE QUERY printAllRelatedItems(vertex<person> seed) FOR GRAPH socialNet SYNTAX V1
{
sourceVertex = {seed};
# -- statements produce equivalent output
# returns all vertices of type either 'person' or 'post' that can be reached
# from the sourceVertex set using one edge of any type
everythingRelated = SELECT v FROM sourceVertex -(:e)- (person|post):v;
# returns all vertices of any type that can be reached from the sourceVertex
# using one edge of any type
# this statement is equivalent to the above one because the graph schema only
# has vertex types of either 'person' or 'post'. if there were more vertex
# types present, these would not be equivalent.
everythingRelated = SELECT v FROM sourceVertex -(:e)- :v;
# --
PRINT everythingRelated;
}GSQL > RUN QUERY printAllRelatedItems("person2")
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"everythingRelated": [
{
"v_id": "0",
"attributes": {
"postTime": "2010-01-12 11:22:05",
"subject": "Graphs"
},
"v_type": "post"
},
{
"v_id": "person3",
"attributes": {
"gender": "Male",
"id": "person3"
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"gender": "Male",
"id": "person1"
},
"v_type": "person"
},
{
"v_id": "3",
"attributes": {
"postTime": "2011-02-05 01:02:44",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "1",
"attributes": {
"postTime": "2011-03-03 23:02:00",
"subject": "tigergraph"
},
"v_type": "post"
}
]}]
}
GSQL > RUN QUERY printAllRelatedItems("person6")
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"everythingRelated": [
{
"v_id": "person4",
"attributes": {
"gender": "Female",
"id": "person4"
},
"v_type": "person"
},
{
"v_id": "10",
"attributes": {
"postTime": "2011-02-04 03:02:31",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "5",
"attributes": {
"postTime": "2011-02-06 01:02:02",
"subject": "tigergraph"
},
"v_type": "post"
},
{
"v_id": "person8",
"attributes": {
"gender": "Male",
"id": "person8"
},
"v_type": "person"
},
{
"v_id": "8",
"attributes": {
"postTime": "2011-02-03 17:05:52",
"subject": "cats"
},
"v_type": "post"
}
]}]
}Vertex and Edge Aliases
Vertex and edge aliases are declared within the FROM clause of a SELECT block, by using the character ":", followed by the alias name. Aliases can be accessed anywhere within the same SELECT block. They are used to reference a single selected vertex or edge of a set. It is through the vertex or edge aliases that the attributes of these vertices or edges can be accessed.
For example, the following code snippets show two different SELECT statements. The first SELECT statement starts from a vertex set called allVertices, and the vertex alias name v can access each individual vertex from allVertices. The second SELECT statement selects a set of edges. It can use the vertex alias s to reference the source vertices, or the alias t to reference the target vertices.
results = SELECT v FROM allVertices:v;
results = SELECT t FROM allVertices:s -()-> :t;The following example shows an edge-based SELECT statement, declaring aliases for all three parts of the edge. In the ACCUM clause, the e and t aliases are assigned to local vertex and edge variables.
results = SELECT v
FROM allVertices:s -(:e)- :t
ACCUM VERTEX v = t, EDGE eg = e;|
We strongly suggest that an alias should be declared with every vertex and edge in the FROM clause, as there are several functions and features only available to vertex and edge aliases. |
SAMPLE
The SAMPLE clause is an optional clause that selects a uniform random sample from the population of edges or target vertices specified in the FROM argument.
|
If you want to sample from a set of vertices directly, not from edges or from neighboring (target) vertices, then the following technique is simpler and faster: |
random = SELECT s
FROM S:s
LIMIT k;The SAMPLE clause draws from the edge population consisting of those edges which satisfy all three parts — source set, edge type, and target type — of the FROM clause. The SAMPLE clause is intended to provide a representative sample of the distribution of edges (or vertices) connected to hub vertices, instead of dealing with all edges. A hub vertex is a vertex with a relatively high degree. (The degree of a vertex is the number of edges which connect to it. If edges are directional, one can distinguish between indegree and outdegree.)
sampleClause := SAMPLE ( expr | expr "%" ) EDGE WHEN condition # sample an absolute number (or a percentage) of edges for each source vertex.
| SAMPLE expr TARGET WHEN condition # sample an absolute number of edges incident to each target vertex.
| SAMPLE expr "%" TARGET PINNED WHEN condition # sample a percentage of edges incident to each target vertex.The expression following SAMPLE specifies the sample size, either an absolute number or a percentage of the population. The expression in sampleClause must evaluate to a positive integer. There are two sampling methods. One is sampling based on edge id. The other is based on target vertex id: if a target vertex id is sampled, all edges from this source vertex to the sampled target vertex are sampled.
|
Note: Currently, the WHEN condition that can be used with a SAMPLE clause is limited strictly to checking if the result of a function call on a vertex is greater than or greater than/equal to some number. |
Given that the sampling is random, some details of each of the example queries may change each time they are run.
The following query displays two modes of sampling: an absolute number of edges from a source vertex and a percentage of edges from a source vertex. We use the computerNet graph (see Appendix D). In computerNet, there are 31 vertices and 43 edges, but only 7 vertices are source vertices. Moreover, c1, c12, and c23 are hub nodes, with at least 10 outgoing edges each. For the absolute count case, we set the size to 1 edge per source vertex, which is equivalent to a random walk. We expect exactly 7 edges to be selected. For the percentage sampling case, we sample 33% of the edges for vertices which have 3 or more outgoing edges. We expect about 15 edges, but the number may vary.
CREATE QUERY sampleEx3() FOR GRAPH computerNet SYNTAX V1
{
MapAccum<STRING,ListAccum<STRING>> @@absEdges; // record each selected edge as (src->tgt)
SumAccum<INT> @@totalAbs;
MapAccum<STRING,ListAccum<STRING>> @@pctEdges; // record each selected edge as (src->tgt)
SumAccum<INT> @@totalPct;
start = {computer.*};
# Sample one outgoing edge per source vertex = Random Walk
absSample = SELECT v FROM start:s -(:e)- :v
SAMPLE 1 EDGE WHEN s.outdegree() >= 1 # sample 1 target vertex from each source vertex
ACCUM @@absEdges += (s.id -> v.id),
@@totalAbs += 1;
PRINT @@totalAbs, @@absEdges;
pctSample = SELECT v FROM start:s -(:e)- :v
SAMPLE 33% EDGE WHEN s.outdegree() >= 3 # select ~1/3 of edges when outdegree >= 3
ACCUM @@pctEdges += (s.id -> v.id),
@@totalPct += 1;
PRINT @@totalPct, @@pctEdges;
}GSQL > RUN QUERY sampleEx3()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [
{
"@@totalAbs": 7,
"@@absEdges": {
"c4": ["c23"],
"c11": ["c12"],
"c10": ["c11"],
"c12": ["c14"],
"c23": ["c26"],
"c14": ["c24"],
"c1": ["c10"]
}
},
{
"@@totalPct": 13,
"@@pctEdges": {
"c4": ["c23"],
"c11": ["c12"],
"c10": ["c11"],
"c12": [
"c14",
"c15",
"c19"
],
"c23": [
"c29",
"c25"
],
"c14": [
"c24",
"c23"
],
"c1": [
"c3",
"c8",
"c2"
]
}
}
]
}Below is an example of using SELECT to only traverse one edge for each source vertex. The vertex-attached accumulators @timesTraversedNoSample and @timesTraversedWithSample are used to keep track of the number of times an edge is traversed to reach the target vertex. Without using sampling, this occurs once for each edge; thus @timesTraversedNoSample has the same number as the in-degree of the vertex. With sampling edges, the number of edges is restricted. This is reflected in the @timesTraversedWithSample accumulator. Notice the difference in the result set. Because only one edge per source vertex is traversed when the SAMPLE clause is used, not all target vertices are reached. The vertex company3 has 3 incident edges, but in one instance of the query execution, it is never reached. Additionally, company2 has 6 incident edges, but only 4 source vertices sampled an edge incident to company2 .
CREATE QUERY sampleEx1() FOR GRAPH workNet SYNTAX V1
{
SumAccum<INT> @timesTraversedNoSample;
SumAccum<INT> @timesTraversedWithSample;
workers = {person.*};
# the 'beforeSample' result set encapsulates the normal functionality of
# a SELECT statement, where 'timesTraversedNoSample' vertex accumulator is increased for
# each edge incident to the vertex.
beforeSample = SELECT v FROM workers:t -(:e)- :v
ACCUM v.@timesTraversedNoSample += 1;
# The 'afterSample' result set is formed by those vertices which can be
# reached when for each source vertex, only one edge is used for traversal.
# This is demonstrated by the values of 'timesTraversedWithSample' vertex accumulator, which
# is increased for each edge incident to the vertex which is used in the
# sample.
afterSample = SELECT v FROM workers:t -(:e)- :v
SAMPLE 1 EDGE WHEN t.outdegree() >= 1 # only use 1 edge from the source vertex
ACCUM v.@timesTraversedWithSample += 1;
PRINT beforeSample;
PRINT afterSample;
}GSQL > RUN QUERY sampleEx1()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [
{"beforeSample": [
{
"v_id": "company4",
"attributes": {
"country": "us",
"@timesTraversedNoSample": 1,
"@timesTraversedWithSample": 1,
"id": "company4"
},
"v_type": "company"
},
{
"v_id": "company5",
"attributes": {
"country": "can",
"@timesTraversedNoSample": 1,
"@timesTraversedWithSample": 1,
"id": "company5"
},
"v_type": "company"
},
{
"v_id": "company3",
"attributes": {
"country": "jp",
"@timesTraversedNoSample": 3,
"@timesTraversedWithSample": 3,
"id": "company3"
},
"v_type": "company"
},
{
"v_id": "company2",
"attributes": {
"country": "chn",
"@timesTraversedNoSample": 6,
"@timesTraversedWithSample": 4,
"id": "company2"
},
"v_type": "company"
},
{
"v_id": "company1",
"attributes": {
"country": "us",
"@timesTraversedNoSample": 6,
"@timesTraversedWithSample": 3,
"id": "company1"
},
"v_type": "company"
}
]},
{"afterSample": [
{
"v_id": "company4",
"attributes": {
"country": "us",
"@timesTraversedNoSample": 1,
"@timesTraversedWithSample": 1,
"id": "company4"
},
"v_type": "company"
},
{
"v_id": "company5",
"attributes": {
"country": "can",
"@timesTraversedNoSample": 1,
"@timesTraversedWithSample": 1,
"id": "company5"
},
"v_type": "company"
},
{
"v_id": "company3",
"attributes": {
"country": "jp",
"@timesTraversedNoSample": 3,
"@timesTraversedWithSample": 3,
"id": "company3"
},
"v_type": "company"
},
{
"v_id": "company2",
"attributes": {
"country": "chn",
"@timesTraversedNoSample": 6,
"@timesTraversedWithSample": 4,
"id": "company2"
},
"v_type": "company"
},
{
"v_id": "company1",
"attributes": {
"country": "us",
"@timesTraversedNoSample": 6,
"@timesTraversedWithSample": 3,
"id": "company1"
},
"v_type": "company"
}
]}
]
}|
Since the PRINT statements are placed at the end of query, the two vertex sets beforeSample and afterSample are almost identical, showing the final values of both accumulators@timesTraversedNoSample and @timesTraversedWithSample. There is one difference: company3 is not included in afterSample because none of the sample-selected edges reached company3. |
WHERE
The WHERE clause is an optional clause that constrains edges and vertices specified in the FROM and SAMPLE clauses.
whereClause := WHERE conditionThe WHERE clause uses a boolean condition to test each vertex or edge in the FROM set (or the sampled vertex and edge sets, if the SAMPLE clause was used).
If the expression evaluates to false for vertex/edge X, then X excluded from further consideration in the result set. The expression may use constants or any variables or parameters within the scope of the SELECT, arithmetic operators (+, -, *, /,%), comparison operators (==, !=, <, <=, >,>=), boolean operators (AND, OR, NOT), set operators (IN, NOT IN) and parentheses to enforce precedence. The WHERE conditional expression may use any of the variables within its scope (global accumulators, vertex set variables, query input parameters, the FROM clause’s vertex and edge sets (or their vertex and edge aliases), or any of the attributes or accumulators of the vertex/edge sets.) For a more formal explanation of condition, see the EBNF definitions of *condition* and expr.
Using built-in vertex and edge attributes and functions, such as .type and .neighbors(), the WHERE clause can be used to implement sophisticated selection rules for the edge traversal. In the following example, the selection conditions are completely specified in the WHERE clause, with no edge types or vertex types mentioned in the FROM clause.
resultSet1 = SELECT v FROM S:v-((E1|E2|E3):e)-(V1|V2):t;
resultSet2 = SELECT v FROM S:v-(:e)-:t
WHERE t.type IN ("V1", "V2") AND
t IN v.neighbors("E1|E2|E3")The following examples demonstrate using the WHERE clause to limit the resulting vertex set based on a vertex attribute.
CREATE QUERY printCatPosts() FOR GRAPH socialNet SYNTAX V1 {
posts = {post.*};
catPosts = SELECT v FROM posts:v # select only those post vertices
WHERE v.subject == "cats"; # which have a subset of 'cats'
PRINT catPosts;
}GSQL > RUN QUERY printCatPosts()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"catPosts": [
{
"v_id": "10",
"attributes": {
"postTime": "2011-02-04 03:02:31",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "9",
"attributes": {
"postTime": "2011-02-05 23:12:42",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "3",
"attributes": {
"postTime": "2011-02-05 01:02:44",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "11",
"attributes": {
"postTime": "2011-02-03 01:02:21",
"subject": "cats"
},
"v_type": "post"
},
{
"v_id": "8",
"attributes": {
"postTime": "2011-02-03 17:05:52",
"subject": "cats"
},
"v_type": "post"
}
]}]
}CREATE QUERY findGraphFocusedPosts() FOR GRAPH socialNet SYNTAX V1
{
posts = {post.*};
results = SELECT v FROM posts:v # select only post vertices
WHERE v.subject IN ("Graph", "tigergraph"); # which have a subject of either 'Graph' or 'tigergraph'
PRINT results;
}GSQL > RUN QUERY findGraphFocusedPosts()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"results": [
{
"v_id": "5",
"attributes": {
"postTime": "2011-02-06 01:02:02",
"subject": "tigergraph"
},
"v_type": "post"
},
{
"v_id": "1",
"attributes": {
"postTime": "2011-03-03 23:02:00",
"subject": "tigergraph"
},
"v_type": "post"
},
{
"v_id": "6",
"attributes": {
"postTime": "2011-02-05 02:02:05",
"subject": "tigergraph"
},
"v_type": "post"
}
]}]
}|
WHERE NOT limitations The NOT operator may not be used in combination with the .type attribute selector. To check if an edge or vertex type is not equal to a given type, use the != operator. See the example below. |
The following example shows the equivalence of using WHERE as a type filter as well as its limitations.
# finds female person in the social network. all of the following statements
# are equivalent (i.e., produce the same results)
CREATE QUERY findFemaleMembers() FOR GRAPH socialNet SYNTAX V1
{
allVertices = {ANY}; # includes all posts and person
females = SELECT v FROM allVertices:v
WHERE v.type == "person" AND
v.gender != "Male";
females = SELECT v FROM allVertices:v
WHERE v.type == "person" AND
v.gender == "Female";
females = SELECT v FROM allVertices:v
WHERE v.type == "person" AND
NOT v.gender == "Male";
females = SELECT v FROM allVertices:v
WHERE v.type != "post" AND
NOT v.gender == "Male";
# does not compile. cannot use NOT operator in combination with type attribute
#females = SELECT v FROM allVertices:v
# WHERE NOT v.type != "person" AND
# NOT v.gender == "Male";
# does not compile. cannot use NOT operator in combination with type attribute
#females = SELECT v FROM allVertices:v
# WHERE NOT v.type == "post" AND
# NOT v.gender == "Male";
personVertices = {person.*};
females = SELECT v FROM personVertices:v
WHERE NOT v.gender == "Male";
females = SELECT v FROM personVertices:v
WHERE v.gender != "Male";
females = SELECT v FROM personVertices:v
WHERE v.gender != "Male" AND true;
females = SELECT v FROM personVertices:v
WHERE v.gender != "Male" OR false;
PRINT females;
}GSQL > RUN QUERY findFemaleMembers()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"females": [
{
"v_id": "person4",
"attributes": {
"gender": "Female",
"id": "person4"
},
"v_type": "person"
},
{
"v_id": "person5",
"attributes": {
"gender": "Female",
"id": "person5"
},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {
"gender": "Female",
"id": "person2"
},
"v_type": "person"
}
]}]
}The following example uses edge attributes to determine which workers are registered as full time for some company.
# find all workers who are full time at some company
CREATE QUERY fullTimeWorkers() FOR GRAPH workNet SYNTAX V1
{
start = {person.*};
fullTimeWorkers = SELECT v FROM start:v -(worksFor:e)- company:t
WHERE e.fullTime; # fullTime is a boolean attribute on the edge
PRINT fullTimeWorkers;
}GSQL > RUN QUERY fullTimeWorkers()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"fullTimeWorkers": [
{
"v_id": "person4",
"attributes": {
"interestList": ["football"],
"skillSet": [ 10, 1, 4 ],
"skillList": [ 4, 1, 10 ],
"locationId": "us",
"interestSet": ["football"],
"id": "person4"
},
"v_type": "person"
},
{
"v_id": "person11",
"attributes": {
"interestList": [ "sport", "football" ],
"skillSet": [10],
"skillList": [10],
"locationId": "can",
"interestSet": [ "football", "sport" ],
"id": "person11"
},
"v_type": "person"
},
{
"v_id": "person10",
"attributes": {
"interestList": [ "football", "sport" ],
"skillSet": [3],
"skillList": [3],
"locationId": "us",
"interestSet": [ "sport", "football" ],
"id": "person10"
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"interestList": [ "management", "financial" ],
"skillSet": [ 3, 2, 1 ],
"skillList": [ 1, 2, 3 ],
"locationId": "us",
"interestSet": [ "financial", "management" ],
"id": "person1"
},
"v_type": "person"
},
{
"v_id": "person6",
"attributes": {
"interestList": [ "music", "art" ],
"skillSet": [ 10, 7 ],
"skillList": [ 7, 10 ],
"locationId": "jp",
"interestSet": [ "art", "music" ],
"id": "person6"
},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {
"interestList": ["engineering"],
"skillSet": [ 6, 5, 3, 2 ],
"skillList": [ 2, 3, 5, 6 ],
"locationId": "chn",
"interestSet": ["engineering"],
"id": "person2"
},
"v_type": "person"
},
{
"v_id": "person8",
"attributes": {
"interestList": ["management"],
"skillSet": [ 2, 5, 1 ],
"skillList": [ 1, 5, 2 ],
"locationId": "chn",
"interestSet": ["management"],
"id": "person8"
},
"v_type": "person"
},
{
"v_id": "person12",
"attributes": {
"interestList": [
"music",
"engineering",
"teaching",
"teaching",
"teaching"
],
"skillSet": [ 2, 5, 1 ],
"skillList": [ 1, 5, 2, 2, 2 ],
"locationId": "jp",
"interestSet": [ "teaching", "engineering", "music" ],
"id": "person12"
},
"v_type": "person"
},
{
"v_id": "person3",
"attributes": {
"interestList": ["teaching"],
"skillSet": [ 6, 1, 4 ],
"skillList": [ 4, 1, 6 ],
"locationId": "jp",
"interestSet": ["teaching"],
"id": "person3"
},
"v_type": "person"
},
{
"v_id": "person9",
"attributes": {
"interestList": [ "financial", "teaching" ],
"skillSet": [ 2, 7, 4 ],
"skillList": [ 4, 7, 2 ],
"locationId": "us",
"interestSet": [ "teaching", "financial" ],
"id": "person9"
},
"v_type": "person"
}
]}]
}|
If multiple edge types are specified in edge-induced selection, the WHERE clause should use OR to separate each edge type or each target vertex type. For example, Multiple Edge Type WHERE clause
The above query is compilable. However, if we use line 5 as the WHERE clause instead, the query is not compilable. The edge-type conflict checking detects an error, because i t uses attributes from both "liked" edges and "friend" edges without separating them out by OR. |
ACCUM and POST-ACCUM
The optional ACCUM and POST-ACCUM clauses enable sophisticated aggregation and other computations across the set of vertices or edges selected by the preceding FROM, SAMPLE, and WHERE clauses. A query can contain one or both of these clauses. The statements in an ACCUM clause are applied for every edge in an edge-induced selection or every vertex in a vertex-induced selection.
If there is more than one statement in the ACCUM clause, the statements are separated by commas and executed sequentially for each selected element. However, the TigerGraph system uses parallelism to improve performance. Within an ACCUM clause, each edge is handled by a separate process. As such, there is no fixed order in which the edges are processed within the ACCUM clause and the edges should not be treated as executing sequentially. The accumulators are mutex variables shared among each of these processes. The results of any accumulation within the ACCUM clause is not complete until all edges are traversed. Any inspection of an intermediate result within the ACCUM is incomplete and may not be that meaningful.
|
The statements within the ACCUM clause are executed sequentially for a given vertex or edge. However, there is no fixed order in which a vertex set or edge set is processed. |
The optional POST-ACCUM clause enables aggregation and other computations across the set of vertices (but not edges) selected by the preceding clauses. POST-ACCUM can be used without ACCUM. If it is preceded by an ACCUM clause, then it can be used for 2-stage accumulative computation: a first stage in ACCUM followed by a second stage in POST-ACCUM.
|
Each statement within the POST-ACCUM clause can refer to either source vertices or target vertices but not both. |
Since the ACCUM clause iterates over edges, and often two edges will connect to the same source vertex or to the same target vertex, the ACCUM clause can be repeated multiple times for one vertex.
|
Operations that are to be performed exactly once per vertex should be performed in the POST-ACCUM clause. |
The primary purpose of the ACCUM or POST-ACCUM clause is to collect information about the graph by updating accumulators (via += or =). See the "Accumulator" section for details on the += operation. However, other kinds of statements (e.g., branching, iteration, local assignments) are permitted to support more complex computations or to log activity. The EBNF syntax below defines the allowable kinds of statements that can occur within an ACCUM or POST-ACCUM. The dmlSubStmt list is similar to the queryBodyStmt list which applies to statements outside of a SELECT block; it is important to note the differences. Each of these statement types is discussed in one of the main sections of this reference document.
accumClause := [perClauseV2] ACCUM dmlSubStmtList
perClauseV2 := PER "(" alias ["," alias] ")"
postAccumClause := POST-ACCUM dmlSubStmtList
dmlSubStmtList := dmlSubStmt ["," dmlSubStmt]*
dmlSubStmt := assignStmt // Assignment
| funcCallStmt // Function Call
| gAccumAccumStmt // Assignment
| lAccumAccumStmt // Assignment
| attrAccumStmt // Assignment
| vAccumFuncCall // Function Call
| localVarDeclStmt // Declaration
| dmlSubCaseStmt // Control Flow
| dmlSubIfStmt // Control Flow
| dmlSubWhileStmt // Control Flow
| dmlSubForEachStmt // Control Flow
| BREAK // Control Flow
| CONTINUE // Control Flow
| insertStmt // Data Modification
| dmlSubDeleteStmt // Data Modification
| printlnStmt // Output
| logStmt // Output|
Note that dml-sub-statements do not include global accumulator assignment statement (gAccumAssignStmt) but global accumulator accumulation statement (gAccumAccumStmt). Global accumulators may perform accumulation += but not assignment "=" within these clauses. |
|
There are additional restrictions on dml-sub level statements:
|
Aliases and ACCUM/POST-ACCUM Iteration Model
To reference each element of the selected set, use the aliases defined in the FROM clause. For example, assume that we have the following aliases:
FROM source:s -(edgeTypes:e)- targetTypes:t # edge-induced selection
FROM source:v # vertex-induced selectionLet (V1, V2,… Vn) be the vertices in the vertex-induced selection . The following pseudocode emulates ACCUM clause behavior.
FOREACH v in (V1,V2,...Vn) DO # iterations may occur in parallel, in unknown order
dmlSubStmts referencing v
DONELet E = (E1, E2,… En) be the edges in the edge-induced selected set. Further, let S = (S1,S1,…Sn) and T= (T1,T2,…Tn) be the multisets (bags) of source vertices and target vertices which correspond to the edge set. S and T are bags, because they can contain repeated elements.
FOREACH i in (1..n) DO # iterations may occur in parallel, in unknown order
dmlSubStmts referencing e, s, t, which really means e_i, s_i, t_i
DONENote that any reference to the source alias s or target alias t is for the endpoint vertices of the current edge.
Similarly, the POST-ACCUM clause acts like a FOREACH loop on the vertex result set specified in the SELECT clause (e.g., either S or T).
Edge/Vertex Type Inference and Conflict
If multiple edge types are specified in edge-induced selection, each ACCUM statement in ACCUM clause checks whether edge types are conflicted. If only a subset of edge types are effective in an ACCUM statement , this statement is not executed on other edge types. For example:
CREATE QUERY multipleEdgeTypeCheckEx(vertex<person> m1) FOR GRAPH socialNet SYNTAX V1 {
ListAccum<STRING> @@testList1, @@testList2, @@testList3;
allUser = {m1};
allUser = SELECT s
FROM allUser:s - ((posted|liked|friend):e) - (post|person):t
ACCUM @@testList1 += to_string(datetime_to_epoch(e.actionTime))
,@@testList2 += t.gender
#,@@testList3 += to_string(datetime_to_epoch(e.actionTime)) + t.gender # illegal
;
PRINT @@testList1, @@testList2, @@testList3;
}In the above example, line 6 is only executed on "liked" edges, because "actionTime" is the attribute of "liked" edge only. Similarly, line 7 is only executed on "friend" edges, because "gender" is the attribute of "person" only, and only "friend" edge uses "person" as target vertex. However, line 8 causes a compilation error, because it uses multiple edges where some edges cannot be supported in a part of the statement, i.e., "liked" edges doesn’t have t.gender, "friend" edges doesn’t have e.actionTime.
|
We strongly suggest that if multiple edge types are specified in edge-induced selection, ACCUM clauses should uses CASE statement (see Section "Control Flow Statements" for more details) to separate the operation on each edge type or each target vertex type (or combination of target vertex type and edge type). The edge-type conflict checking then checks the ACCUM statement inside each THEN/ELSE blocks based on the condition. For example, Multiple Edge Type ACCUM statement check 2
The above query is compilable. However, if we switch line 8 and line 10, the edge-type conflict checking generates errors because "liked" edges doesn’t support t.gender and "friend" edges doesn’t support e.actionTime. |
Similar to the ACCUM clause, if multiple source/target vertex types are specified in edge-induced selection and the POST-ACCUM clauses accesses source/target vertex, each ACCUM statement in POST-ACCUM clause checks whether source/target vertex types are conflicted. If only a subset of source/target vertex types are effective in a POST-ACCUM statement, this statement is not executed on other source/target vertex types.
|
Similar to ACCUM clause, we strongly suggest that if multiple source/target vertex types are specified in edge-induced selection and the POST-ACCUM clauses accesses source/target vertex, POST-ACCUM clauses should uses CASE statement (see Section "Control Flow Statements" for more details) to separate the operation on each source/target vertex type. The vertex type conflict checking then checks the ACCUM statement inside each THEN/ELSE blocks based on the condition. |
Rules for Updating Vertex-Attached Accumulators
Prior to v1.0, a vertex-attached accumulator could only be updated in an ACCUM or POST-ACCUM clause and only if its vertex was selected for by the preceding FROM-SAMPLE-WHERE clauses.
Beginning in v1.0, there are additional circumstances where a vertex-attached accumulator may be updated. Vertices which are referenced via a vertex-attached accumulator of a selected vertex may have their vertex-attached accumulators updated in the ACCUM clause (but not in the POST-ACCUM clause). That is, a vertex referenced by an selected vertex can be updated, with some limitations explained below. Some examples will help to illustrate this more complex condition.
-
Suppose a query declares a vertex-attached accumulator which holds vertex information . We call this a vertex-holding accumulator . This could take several forms:
-
A scalar accumulator, e.g., MaxAccum< VERTEX > @maxV;
-
A collection accumulator: e.g., ListAccum< VERTEX > @listV;
-
An accumulator containing tuple(s), where the tuple type contains a VERTEX field.
-
-
If a vertex V is selected, then not only can V’s accumulators be updated, but the vertices stored in its vertex-holding accumulators can also be updated, in the ACCUM clause.
-
Before these indirectly referenced vertices can be used, they need to be activated . There are two ways to activate an indirect vertex:
-
A vertex from a vertex-holding accumulator is first assigned to a local vertex variable. The vertex can then be updated through the local vertex variable.
-
ACCUM
VERTEX<person> mx = tgt.@maxV, # assign to local variable
mx.@curId += src.id # access via local variable-
A FOREACH loop can iterate on a vertex-holding collection accumulator. The vertices can now be updated through the loop variable.
ACCUM
FOREACH vtx IN src.@setIds DO # iterate on collection accumulator
vtx.@curId += tgt.id # access via loop variable
END|
The following uses are NOT supported by the new rules:
|
The following query demonstrates updates to indirectly activated vertices.
CREATE QUERY vUpdateIndirectAccum() FOR GRAPH socialNet SYNTAX V1 {
SetAccum<VERTEX<person>> @posters;
SetAccum<VERTEX<person>> @fellows;
Persons = {person.*};
# To each post, attach a list of persons who liked the post
likedPosts = SELECT p
FROM Persons:src -(liked:e)- post:p
ACCUM
p.@posters += src;
# To each person who liked a post, attach a list of everyone
# who also liked one of this person's liked posts.
likedPosts = SELECT src
FROM likedPosts:src
ACCUM
FOREACH v IN src.@posters DO
v.@fellows += src.@posters
END
ORDER BY src.subject;
PRINT Persons[Persons.@fellows];
}GSQL > RUN QUERY vUpdateIndirectAccess()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"Persons": [
{
"v_id": "person4",
"attributes": {"Persons.@fellows": [
"person8",
"person4"
]},
"v_type": "person"
},
{
"v_id": "person3",
"attributes": {"Persons.@fellows": [ "person2", "person1", "person3" ]},
"v_type": "person"
},
{
"v_id": "person7",
"attributes": {"Persons.@fellows": ["person7"]},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {"Persons.@fellows": [ "person2", "person1", "person3" ]},
"v_type": "person"
},
{
"v_id": "person5",
"attributes": {"Persons.@fellows": ["person5"]},
"v_type": "person"
},
{
"v_id": "person6",
"attributes": {"Persons.@fellows": ["person6"]},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {"Persons.@fellows": [ "person2", "person1", "person3" ]},
"v_type": "person"
},
{
"v_id": "person8",
"attributes": {"Persons.@fellows": [ "person8", "person4" ]},
"v_type": "person"
}
]}]
}ACCUM and POST-ACCUM Examples
We now show several examples. This example demonstrates how ACCUM or POST-ACCUM can be used to count the number of vertices in the given set.
#Show Accum PostAccum Behavior
CREATE QUERY accumPostAccumSemantics() FOR GRAPH workNet SYNTAX V1 {
SumAccum<INT> @@vertexOnlyAccum;
SumAccum<INT> @@vertexOnlyPostAccum;
SumAccum<INT> @@vertexOnlyWhereAccum;
SumAccum<INT> @@vertexOnlyWherePostAccum;
SumAccum<INT> @@sourceWithEdgeAccum;
SumAccum<INT> @@sourceWithEdgePostAccum;
SumAccum<INT> @@targetWithEdgeAccum;
SumAccum<INT> @@targetWithEdgePostAccum;
#Seed start set with all company vertices
start = {company.*};
#Select all vertices in source set start
selectVertexSet = SELECT v from start:v
#Happens once for each vertex discovered
ACCUM @@vertexOnlyAccum += 1
#Happens once for each vertex in the result set "v"
POST-ACCUM @@vertexOnlyPostAccum += 1;
#Select all vertices in source set start with a where constraint
selectVertexSetWhere = SELECT v from start:v WHERE (v.country == "us")
#Happens once for each vertex discovered that also
# meets the constraint condition
ACCUM @@vertexOnlyWhereAccum += 1
#Happens once for each vertex in the result set "v"
POST-ACCUM @@vertexOnlyWherePostAccum += 1;
#Select all source "s" vertices in set start and explore all "worksFor" edge paths
selectSourceWithEdge = SELECT s from start:s -(worksFor)- :t
#Happens once for each "worksFor" edge discovered
ACCUM @@sourceWithEdgeAccum += 1
#Happens once for each vertex in result set "s" (source)
POST-ACCUM @@sourceWithEdgePostAccum += 1;
#Select all target "t" vertices found from exploring all "worksFor" edge paths from set start
selectTargetWithEdge = SELECT t from start:s -(worksFor)- :t
#Happens once for each "worksFor" edge discovered
ACCUM @@targetWithEdgeAccum += 1
#Happens once for each vertex in result set "t" (target)
POST-ACCUM @@targetWithEdgePostAccum += 1;
PRINT @@vertexOnlyAccum;
PRINT @@vertexOnlyPostAccum;
PRINT @@vertexOnlyWhereAccum;
PRINT @@vertexOnlyWherePostAccum;
PRINT @@sourceWithEdgeAccum;
PRINT @@sourceWithEdgePostAccum;
PRINT @@targetWithEdgeAccum;
PRINT @@targetWithEdgePostAccum;
}GSQL > RUN QUERY accumPostAccumSemantics()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [
{"@@vertexOnlyAccum": 5},
{"@@vertexOnlyPostAccum": 5},
{"@@vertexOnlyWhereAccum": 2},
{"@@vertexOnlyWherePostAccum": 2},
{"@@sourceWithEdgeAccum": 17},
{"@@sourceWithEdgePostAccum": 5},
{"@@targetWithEdgeAccum": 17},
{"@@targetWithEdgePostAccum": 12}
]
}This example uses ACCUM to find all the subjects a user posted about.
# For each person, make a list of all their post subjects
CREATE QUERY userPosts() FOR GRAPH socialNet SYNTAX V1 {
ListAccum<STRING> @personPosts;
start = {person.*};
# Find all user post topics and append them to the vertex list accum
userPostings = SELECT s FROM start:s -(posted)- :g
ACCUM s.@personPosts += g.subject;
PRINT userPostings;
}GSQL > RUN QUERY userPosts()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"userPostings": [
{
"v_id": "person4",
"attributes": {
"gender": "Female",
"@personPosts": ["cats"],
"id": "person4"
},
"v_type": "person"
},
{
"v_id": "person3",
"attributes": {
"gender": "Male",
"@personPosts": ["query languages"],
"id": "person3"
},
"v_type": "person"
},
{
"v_id": "person7",
"attributes": {
"gender": "Male",
"@personPosts": [ "cats", "tigergraph" ],
"id": "person7"
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"gender": "Male",
"@personPosts": ["Graphs"],
"id": "person1"
},
"v_type": "person"
},
/*** other vertices omitted ***/
]}]
}This example shows each person’s posted vertices and each person’s like behaviors (liked edges).
ACCUM<VERTEX> and ACCUM<EDGE> Example# Show each user's post and liked post time
CREATE QUERY userPosts2() FOR GRAPH socialNet SYNTAX V1 {
ListAccum<VERTEX> @personPosts;
ListAccum<EDGE> @personLikedInfo;
start = {person.*};
# Find all user post topics and append them to the vertex list accum
userPostings = SELECT s FROM start:s -(posted)- :g
ACCUM s.@personPosts += g;
userPostings = SELECT s from start:s -(liked:e)- :g
ACCUM s.@personLikedInfo += e;
PRINT start;
}GSQL > RUN QUERY userPosts2()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"start": [
{
"v_id": "person4",
"attributes": {
"gender": "Female",
"@personPosts": ["3"],
"id": "person4",
"@personLikedInfo": [{
"from_type": "person",
"to_type": "post",
"directed": true,
"from_id": "person4",
"to_id": "4",
"attributes": {"actionTime": "2010-01-13 03:16:05"},
"e_type": "liked"
}]
},
"v_type": "person"
},
{
"v_id": "person7",
"attributes": {
"gender": "Male",
"@personPosts": [ "9", "6" ],
"id": "person7",
"@personLikedInfo": [{
"from_type": "person",
"to_type": "post",
"directed": true,
"from_id": "person7",
"to_id": "10",
"attributes": {"actionTime": "2010-01-12 11:22:05"},
"e_type": "liked"
}]
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"gender": "Male",
"@personPosts": ["0"],
"id": "person1",
"@personLikedInfo": [{
"from_type": "person",
"to_type": "post",
"directed": true,
"from_id": "person1",
"to_id": "0",
"attributes": {"actionTime": "2010-01-11 11:32:00"},
"e_type": "liked"
}]
},
"v_type": "person"
},
/*** other vertices omitted ***/
]}]
}This example counts the total number of times each topic is used.
# Show number of total posts by topic
CREATE QUERY userPostsByTopic() FOR GRAPH socialNet SYNTAX V1 {
MapAccum<STRING, INT> @@postTopicCounts;
start = {person.*};
# Append subject and update the appearance count in the global map accum
posts = SELECT g FROM start -(posted)- :g
ACCUM @@postTopicCounts += (g.subject -> 1);
PRINT @@postTopicCounts;
}GSQL > RUN QUERY userPostsByTopic()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"@@postTopicCounts": {
"cats": 5,
"coffee": 1,
"query languages": 1,
"Graphs": 2,
"tigergraph": 3
}}]
}This is an example of using ACCUM and POST-ACCUM in conjunction. The ACCUM traverses the graph and finds all people who live and work in the same country. After this is determined, POST-ACCUM examines each vertex (person) to see if they work where they live.
#Show all person who both work and live in the same country
CREATE QUERY residentEmployees() FOR GRAPH workNet SYNTAX V1 {
ListAccum<STRING> @company;
OrAccum @worksAndLives;
start = {person.*};
employees = SELECT s FROM start:s -(worksFor)- :c
#If a person works for a company in the same country where they live
# add the company to the list
ACCUM CASE WHEN (s.locationId == c.country) THEN
s.@company += c.id
END
#Check each vertex and see if a person works where they live
POST-ACCUM CASE WHEN (s.@company.size() > 0) THEN
s.@worksAndLives += True
ELSE
s.@worksAndLives += False
END;
PRINT employees WHERE (employees.@worksAndLives == True);
}GSQL > RUN QUERY residentEmployees()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"employees": [
{
"v_id": "person11",
"attributes": {
"interestList": [
"sport",
"football"
],
"skillSet": [10],
"skillList": [10],
"@worksAndLives": true,
"locationId": "can",
"interestSet": [ "football", "sport" ],
"id": "person11",
"@company": ["company5"]
},
"v_type": "person"
},
{
"v_id": "person10",
"attributes": {
"interestList": [ "football", "sport" ],
"skillSet": [3],
"skillList": [3],
"@worksAndLives": true,
"locationId": "us",
"interestSet": [ "sport", "football" ],
"id": "person10",
"@company": ["company1"]
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"interestList": [ "management", "financial" ],
"skillSet": [ 3, 2, 1 ],
"skillList": [ 1, 2, 3 ],
"@worksAndLives": true,
"locationId": "us",
"interestSet": [ "financial", "management" ],
"id": "person1",
"@company": ["company1"]
},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {
"interestList": ["engineering"],
"skillSet": [ 6, 5, 3, 2 ],
"skillList": [ 2, 3, 5, 6 ],
"@worksAndLives": true,
"locationId": "chn",
"interestSet": ["engineering"],
"id": "person2",
"@company": ["company2"]
},
"v_type": "person"
}
]}]
}This is an example of a POST-ACCUM only that counts the number people with a particular gender.
#Count the number of person of a given gender
CREATE QUERY personGender(STRING gender) FOR GRAPH socialNet SYNTAX V1 {
SumAccum<INT> @@genderCount;
start = {ANY};
# Select all person vertices and check the gender attribute
friends = SELECT v FROM start:v
WHERE v.type == "person"
POST-ACCUM CASE WHEN (start.gender == gender) THEN
@@genderCount += 1
END;
PRINT @@genderCount;
}GSQL > RUN QUERY personGender("Female")
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"@@genderCount": 3}]
}HAVING
The optional HAVING clause provides constraints on the result set of the SELECT. The constraints are applied after ACCUM and POST-ACCUM actions. This differs from the WHERE clause, which is applied before the ACCUM and POST-ACCUM actions.
havingClause := HAVING conditionThe condition in a HAVING clause is applied to each vertex in the SELECT set (either source or target vertices) which also fulfilled the FROM and WHERE conditions.
The HAVING clause is intended to test one or more of the accumulator variables that were updated in the ACCUM or POST-ACCUM clause, though the condition may be anything that equates to a boolean value.
If the condition is false for a particular vertex, then that vertex is excluded from the result set.
The following example demonstrates using the HAVING clause to constrain a result set based on the vertex accumulator variable which was updated during the ACCUM clause.
# find all persons meeting a given activityThreshold, based on how many posts or likes a person has made
CREATE QUERY activeMembers(int activityThreshold) FOR GRAPH socialNet SYNTAX V1
{
SumAccum<int> @activityAmount;
start = {person.*};
result = SELECT v FROM start:v -(:e)- post:tgt
ACCUM v.@activityAmount +=1
HAVING v.@activityAmount >= activityThreshold;
PRINT result;
}If the activityThreshold parameter is set to 3, the query returns 5 vertices:
GSQL > RUN QUERY activeMembers(3)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"result": [
{
"v_id": "person7",
"attributes": {
"gender": "Male",
"@activityAmount": 3,
"id": "person7"
},
"v_type": "person"
},
{
"v_id": "person5",
"attributes": {
"gender": "Female",
"@activityAmount": 3,
"id": "person5"
},
"v_type": "person"
},
{
"v_id": "person6",
"attributes": {
"gender": "Male",
"@activityAmount": 3,
"id": "person6"
},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {
"gender": "Female",
"@activityAmount": 3,
"id": "person2"
},
"v_type": "person"
},
{
"v_id": "person8",
"attributes": {
"gender": "Male",
"@activityAmount": 3,
"id": "person8"
},
"v_type": "person"
}
]}]
}If the activityThreshold parameter is set to 2, the query would return 8 vertices. With activityThreshold = 4, the query would return no vertices.
The following example demonstrates the equivalence of a SELECT statement in which the condition for the HAVING clause is always true.
# find all person meeting a given activityThreshold, based on how many posts or likes a person has made
CREATE QUERY printMemberActivity() FOR GRAPH socialNet SYNTAX V1
{
SumAccum<int> @activityAmount;
start = {person.*};
### --- equivalent statements -----
result = SELECT v FROM start:v -(:e)- post:tgt
ACCUM v.@activityAmount +=1
HAVING true;
result = SELECT v FROM start:v -(:e)- post:tgt
ACCUM v.@activityAmount +=1;
### -----
PRINT result;
}GSQL > RUN QUERY printMemberActivity()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"result": [
{
"v_id": "person4",
"attributes": {
"gender": "Female",
"@activityAmount": 4,
"id": "person4"
},
"v_type": "person"
},
{
"v_id": "person3",
"attributes": {
"gender": "Male",
"@activityAmount": 4,
"id": "person3"
},
"v_type": "person"
},
{
"v_id": "person7",
"attributes": {
"gender": "Male",
"@activityAmount": 6,
"id": "person7"
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"gender": "Male",
"@activityAmount": 4,
"id": "person1"
},
"v_type": "person"
},
{
"v_id": "person5",
"attributes": {
"gender": "Female",
"@activityAmount": 6,
"id": "person5"
},
"v_type": "person"
},
{
"v_id": "person6",
"attributes": {
"gender": "Male",
"@activityAmount": 6,
"id": "person6"
},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {
"gender": "Female",
"@activityAmount": 6,
"id": "person2"
},
"v_type": "person"
},
{
"v_id": "person8",
"attributes": {
"gender": "Male",
"@activityAmount": 6,
"id": "person8"
},
"v_type": "person"
}
]}]
}The following shows an example of equivalent result sets from using WHERE vs. HAVING. Recall that the WHERE clause is evaluated before the ACCUM and that the HAVING clause is evaluated after the ACCUM. Both constrain the result set based on a condition that vertices must meet.
# Compute the total post activity for each male person.
# Because the gender of the vertex does not change, evaluating whether the person vertex
# is male before (WHERE) the ACCUM clause or after (HAVING) the ACCUM clause does not
# change the result. However, if the condition in the HAVING clause could change within
# the ACCUM clause, these statements would produce different results.
CREATE QUERY activeMaleMembers() FOR GRAPH socialNet SYNTAX V1
{
SumAccum<INT> @activityAmount;
start = {person.*};
### --- statements produce equivalent results
result1 = SELECT v FROM start:v -(:e)- post:tgt
WHERE v.gender == "Male"
ACCUM v.@activityAmount +=1;
result2 = SELECT v FROM start:v -(:e)- post:tgt
ACCUM v.@activityAmount +=1
HAVING v.gender == "Male";
PRINT result1;
PRINT result2;
}[
{
"result1": [
{
"attributes": {
"@activityAmount": 6,
"gender": "Male",
"id": "person7"
},
"v_id": "person7",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 4,
"gender": "Male",
"id": "person3"
},
"v_id": "person3",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 6,
"gender": "Male",
"id": "person8"
},
"v_id": "person8",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 6,
"gender": "Male",
"id": "person6"
},
"v_id": "person6",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 4,
"gender": "Male",
"id": "person1"
},
"v_id": "person1",
"v_type": "person"
}
]
},
{
"result2": [
{
"attributes": {
"@activityAmount": 4,
"gender": "Male",
"id": "person1"
},
"v_id": "person1",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 4,
"gender": "Male",
"id": "person3"
},
"v_id": "person3",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 6,
"gender": "Male",
"id": "person6"
},
"v_id": "person6",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 6,
"gender": "Male",
"id": "person7"
},
"v_id": "person7",
"v_type": "person"
},
{
"attributes": {
"@activityAmount": 6,
"gender": "Male",
"id": "person8"
},
"v_id": "person8",
"v_type": "person"
}
]
}
]The following example has a compilation error because the result set is taken from the source vertices, but the HAVING condition is checking the target vertices.
# find all person having a post subject about cats
# This query is illegal because the having condition is testing the wrong vertex set
CREATE QUERY printMemberAboutCats() FOR GRAPH socialNet SYNTAX V1
{
start = {person.*};
result = SELECT v FROM start:v -(:e)- post:tgt
HAVING tgt.subject == "cats";
PRINT result;
}> gsql printMemberAboutCats.gsql
Semantic Check Error in query printMemberAboutCats (SEM-50): line 8, col 33
The SELECT block selects src, but the HAVING clause uses tgtORDER BY
The optional ORDER BY clause sorts the result set.
orderClause := ORDER BY expr [ASC | DESC] ["," expr [ASC | DESC]]*ASC specifies ascending order (least value first), and DESC specifies descending order (greatest value first). If neither is specified, then ascending order is used. Each expr must refer to the attributes or accumulators of a member of the result set, and the expr must evaluate to a sortable value (e.g., a number or a string). ORDER BY offers hierarchical sorting by allowing a comma-separated list of expressions, sorting first by the leftmost expr. It uses the next expression only to sort items where the current sort expr results in identical values. Any items in the result set which cannot be sorted (because the sort expressions do not pertain to them) will appear at the end of the set, after the sorted items.
|
In tabular SELECT queries, the ORDER BY expressions may only be SELECT column aliases. |
The following example demonstrates the use of ORDER BY with multiple expressions. The returned vertex set is first ordered by the number of friends of the vertex, and then ordered by the number of coworkers of that vertex.
# find the most popular people, sorting first based on the number as friends
# and then in case of a tie by the number of coworkers
CREATE QUERY topPopular() FOR GRAPH friendNet SYNTAX V1
{
SumAccum<INT> @numFriends;
SumAccum<INT> @numCoworkers;
start = {person.*};
result = SELECT v FROM start -((friend|coworker):e)- person:v
ACCUM CASE WHEN e.type == "friend" THEN v.@numFriends += 1
WHEN e.type == "coworker" THEN v.@numCoworkers += 1
END
ORDER BY v.@numFriends DESC, v.@numCoworkers DESC;
PRINT result;
}GSQL > RUN QUERY topPopular()
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"result": [
{
"v_id": "person9",
"attributes": {
"@numCoworkers": 3,
"@numFriends": 5,
"id": "person9"
},
"v_type": "person"
},
{
"v_id": "person8",
"attributes": {
"@numCoworkers": 1,
"@numFriends": 4,
"id": "person8"
},
"v_type": "person"
},
{
"v_id": "person12",
"attributes": {
"@numCoworkers": 1,
"@numFriends": 4,
"id": "person12"
},
"v_type": "person"
},
{
"v_id": "person6",
"attributes": {
"@numCoworkers": 4,
"@numFriends": 3,
"id": "person6"
},
"v_type": "person"
},
{
"v_id": "person1",
"attributes": {
"@numCoworkers": 3,
"@numFriends": 3,
"id": "person1"
},
"v_type": "person"
},
{
"v_id": "person4",
"attributes": {
"@numCoworkers": 5,
"@numFriends": 2,
"id": "person4"
},
"v_type": "person"
},
{
"v_id": "person3",
"attributes": {
"@numCoworkers": 3,
"@numFriends": 2,
"id": "person3"
},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {
"@numCoworkers": 3,
"@numFriends": 2,
"id": "person2"
},
"v_type": "person"
},
{
"v_id": "person10",
"attributes": {
"@numCoworkers": 1,
"@numFriends": 2,
"id": "person10"
},
"v_type": "person"
},
{
"v_id": "person7",
"attributes": {
"@numCoworkers": 6,
"@numFriends": 1,
"id": "person7"
},
"v_type": "person"
},
{
"v_id": "person5",
"attributes": {
"@numCoworkers": 5,
"@numFriends": 1,
"id": "person5"
},
"v_type": "person"
},
{
"v_id": "person11",
"attributes": {
"@numCoworkers": 1,
"@numFriends": 1,
"id": "person11"
},
"v_type": "person"
}
]}]
}LIMIT
The optional LIMIT clause sets constraints on the number and ranking of items included in the final result set.
limitClause := LIMIT ( expr | expr "," expr | expr OFFSET expr )Each of the expr must evaluate to a nonnegative integer. To understand LIMIT, note that the tentative result set is held in the computer as a list of vertices. If the query has an ORDER BY clause, the order is specified; otherwise the list order is unknown. Assume we number the vertices as v_1 , v_2 , …, v_n . The LIMIT clause specifies a range of vertices, starting from a lower position in the list to an upper position.
There are three forms:
result = SELECT v FROM S -(:e)- :v LIMIT k; # case 1: k = Count
result = SELECT v FROM S -(:e)- :v LIMIT j, k; # case 2: j = Offset from the start of the list, k = Count
result = SELECT v FROM S -(:e)- :v LIMIT k OFFSET j; # case 3: k = Count, j = Offset from the start of the listCase 1: LIMIT k
-
When a single expr is provided, LIMIT returns the first k elements from the tentative result set. If there are fewer than k elements available, then all elements will be returned in the result set. If k=5 and the tentative result set has at least 5 items, then the final result list will be [ v_1 , v_2 , v_3 , v_4 , v_5 ].
Case 2: LIMIT j, k
-
When a comma separates two expressions, LIMIT treats the first expression j as an offset. That is, it skips the first j items in the list. The second expr k tells the maximum number of items items to include. If the list has at least 7 items, then LIMIT 2, 5 would return [ v_3 , v_4 , v_5, v_6 , v_7 ].
Case 3: LIMIT k OFFSET j
-
The behavior of Case 3 is the same as that of Case 2, except that the syntax is different. The keyword OFFSET separates the two expressions, and the count comes before the offset, rather than vice versa. If the list has at least 7 items, then LIMIT 5 OFFSET 2 would return [ v_3 , v_4 , v_5, v_6 , v_7 ].
If any of the expressions evaluate to a negative integer, the results are undefined.
|
OFFSET is intended for result sets which are in a known order. It is a compile time error to use OFFSET without the ORDER BY clause. |
The following examples demonstrate the various forms of the LIMIT clause.
The first example shows the LIMIT clause when used as an upper limit. It returns a result set with a maximum size of 4 elements in the set.
CREATE QUERY limitEx1(INT k) FOR GRAPH friendNet SYNTAX V1
{
start = {person.*};
result1 = SELECT v FROM start:v
ORDER BY v.id
LIMIT k;
PRINT result1[result1.id]; // api v2
}GSQL > RUN QUERY limitEx1(4)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"result1": [
{
"v_id": "person1",
"attributes": {"result1.id": "person1"},
"v_type": "person"
},
{
"v_id": "person10",
"attributes": {"result1.id": "person10"},
"v_type": "person"
},
{
"v_id": "person11",
"attributes": {"result1.id": "person11"},
"v_type": "person"
},
{
"v_id": "person12",
"attributes": {"result1.id": "person12"},
"v_type": "person"
}
]}]
}The following example shows how to use the LIMIT clause with an offset.
CREATE QUERY limitEx2(INT j, INT k) FOR GRAPH friendNet SYNTAX V1
{
start = {person.*};
result2 = SELECT v FROM start:v
ORDER BY v.id
LIMIT j, k;
PRINT result2[result2.id]; // api v2
}GSQL > RUN QUERY limitEx2(2,3)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"result2": [
{
"v_id": "person11",
"attributes": {"result2.id": "person11"},
"v_type": "person"
},
{
"v_id": "person12",
"attributes": {"result2.id": "person12"},
"v_type": "person"
},
{
"v_id": "person2",
"attributes": {"result2.id": "person2"},
"v_type": "person"
}
]}]
}The following example shows the alternative syntax for a result size limit with an offset. This time we try larger values for offset and size. In a large data set, limitTest(5,20) might return 20 vertices, but since we don’t have 25 vertices in the original data, the output was fewer than 20 vertices.
CREATE QUERY limitEx3(INT j, INT k) FOR GRAPH friendNet SYNTAX V1
{
start = {person.*};
result3 = SELECT v FROM start:v
ORDER BY v.id
LIMIT k OFFSET j;
PRINT result3[result3.id]; // api v2
}GSQL > RUN QUERY limitEx3(5,20)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"result3": [
{
"v_id": "person3",
"attributes": {"result3.id": "person3"},
"v_type": "person"
},
{
"v_id": "person4",
"attributes": {"result3.id": "person4"},
"v_type": "person"
},
{
"v_id": "person5",
"attributes": {"result3.id": "person5"},
"v_type": "person"
},
{
"v_id": "person6",
"attributes": {"result3.id": "person6"},
"v_type": "person"
},
{
"v_id": "person7",
"attributes": {"result3.id": "person7"},
"v_type": "person"
},
{
"v_id": "person8",
"attributes": {"result3.id": "person8"},
"v_type": "person"
},
{
"v_id": "person9",
"attributes": {"result3.id": "person9"},
"v_type": "person"
}
]}]
}