Get Set
Introduction
In this tutorial, we will show you how to create a graph schema, load data in your graph, write simple parameterized queries, and run your queries. Before you start, you need to have installed the TigerGraph system, verified that it is working, and cleared out any previous data. It’ll also help to become familiar with our graph terminology.
What is a Graph?
A graph is a collection of data entities and the connections between them. That is, it’s a network of data entities.
Many people call a data entity a node ; at TigerGraph we called it a vertex. The plural is vertices. We call a connection an edge. Both vertices and edges can have properties or attributes. The figure below is a visual representation of a graph containing 7 vertices (shown as circles) and 7 edges (the lines).
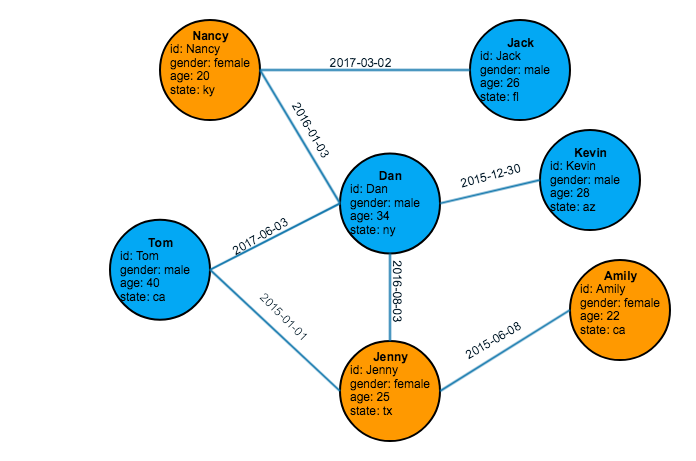
A graph schema is the model which describes the types of vertices (nodes) and edge (connections) which can appear in your graph. The graph above has one type of vertex (person) and one type of edge (friendship).
A schema diagram looks like a small graph, except each node represents one type of vertex, and each link represents one type of edge.
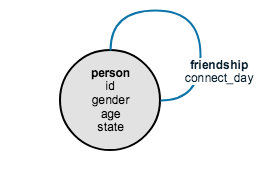
The friendship loop shows that a friendship is between a person and another person.
Data Set
For this tutorial, we will create and query the simple friendship social graph shown in Figure Friendship Social Graph. The data for this graph consists of two files in csv (comma-separated values) format. To follow along with this tutorial, please save these two files, person.csv and friendship.csv, to your TigerGraph local disk. In our running example, we use the /home/tigergraph/ folder to store the two csv files.
name,gender,age,state
Tom,male,40,ca
Dan,male,34,ny
Jenny,female,25,tx
Kevin,male,28,az
Amily,female,22,ca
Nancy,female,20,ky
Jack,male,26,flperson1,person2,date
Tom,Dan,2017-06-03
Tom,Jenny,2015-01-01
Dan,Jenny,2016-08-03
Jenny,Amily,2015-06-08
Dan,Nancy,2016-01-03
Nancy,Jack,2017-03-02
Dan,Kevin,2015-12-30Prepare Your TigerGraph Environment
First, let’s check that you can access GSQL.
-
Open a Linux shell.
-
Type gsql as below. A GSQL shell prompt should appear as below.
Linux Shell$ gsql GSQL > -
If the GSQL shell does not launch, try resetting the system with "gadmin start all". If you need further help, please see manage TigerGraph with gadmin.
If this is your first time using GSQL, the TigerGraph data store is probably empty. However, if you or someone else has already been working on the system, there may already be a database. You can check by listing out the database catalog with the "ls" command. This is what should look like if it is empty:
GSQL > ls
---- Global vertices, edges, and all graphs
Vertex Types:
Edge Types:
Graphs:
Jobs:
Json API version: v2If the data catalog is not empty, you will need to empty it to start this tutorial. We’ll assume you have your coworkers' permission. Use the command DROP ALL to delete all the database data, its schema, and all related definitions. This command takes about a minute to run.
GSQL > drop all
Dropping all, about 1 minute ...
Abort all active loading jobs
[ABORT_SUCCESS] No active Loading Job to abort.
Shutdown restpp gse gpe ...
Graph store /usr/local/tigergraph/gstore/0/ has been cleared!
Everything is dropped.|
Restarting TigerGraph If you need to restart TigerGraph for any reason, use the following command sequence: Linux Shell - Restarting TigerGraph services
|
|
Running GSQL commands from Linux You can also run GSQL commands from a Linux shell. To run a single command, just use "gsql" followed by the command line enclosed in single quotes. (The quotes aren’t necessary if there is no parsing ambiguity; it’s safer to just use them.) For example, Linux shell - GSQL commands from a Linux shell
You can also execute a series of commands which you have stored in a file, by simply invoking "gsql" following by the name of the file. |
When you are done, you can exit the GSQL shell with the command "quit" (without the quotes).