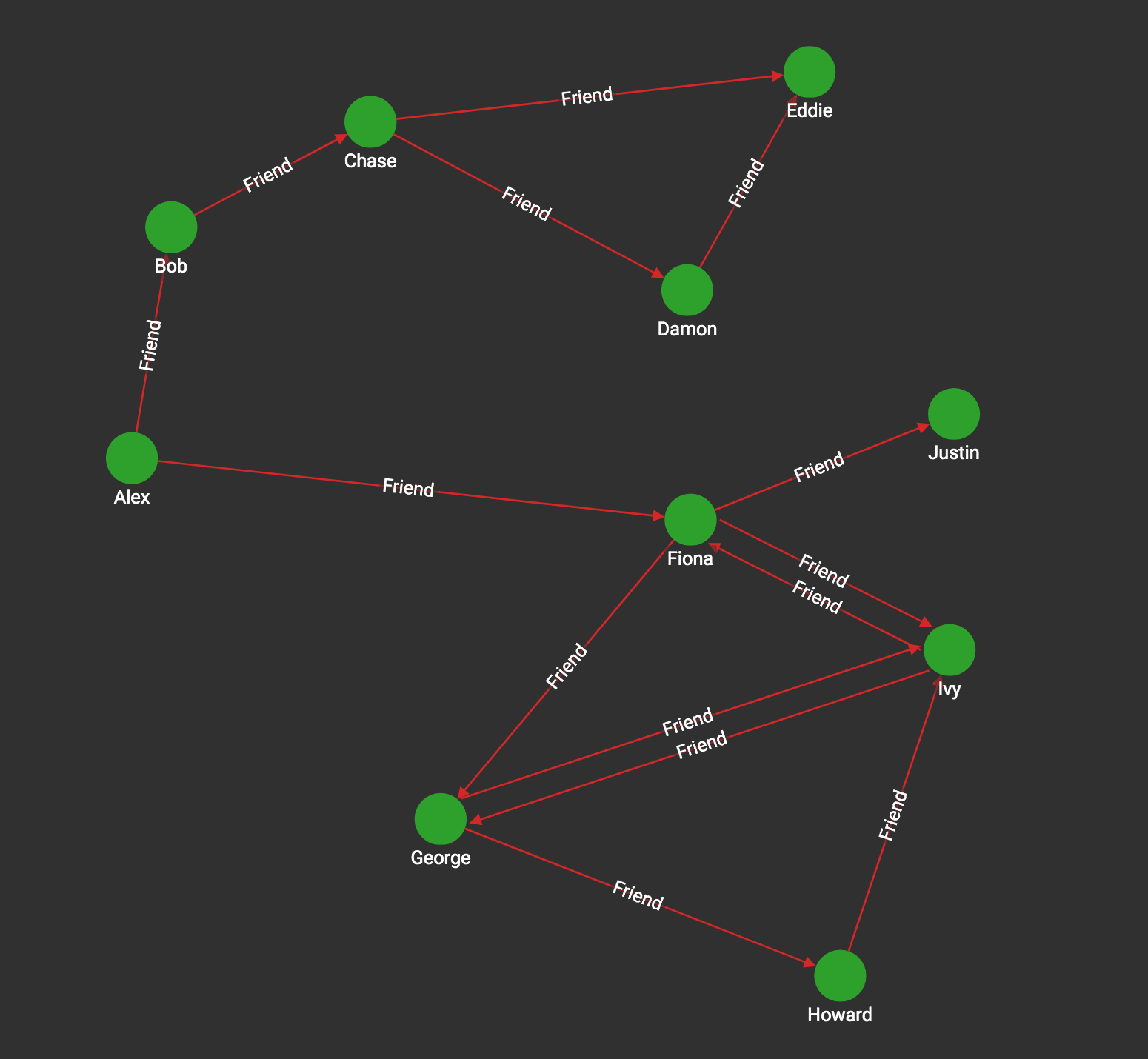
Cycle Detection
The Cycle Detection problem seeks to find all the cycles (loops) in a graph. We apply the usual restriction that the cycles must be "simple cycles", that is, they must be paths that start and end at the same vertex but otherwise never visit any vertex twice.
There are two versions of the task: for directed graphs and undirected graphs. The GSQL algorithm library currently supports only directed cycle detection. The Rocha—Thatte algorithm is an efficient distributed algorithm, which detects all the cycles in a directed graph. The algorithm will self-terminate, but it is also possible to stop at k iterations, which finds all the cycles having lengths up to k edges.
The basic idea of the algorithm is to (potentially) traverse every edge in parallel, again and again, forming all possible paths. At each step, if a path forms a cycle, it records it and stops extending it. More specifically:
Initialization
For each vertex, record one path consisting of its own ID. Mark the vertex as Active.
Iteration steps:
For each Active vertex v:
-
Send its list of paths to each of its out-neighbors.
-
Inspect each path P in the list of the paths received:
-
If the first ID in P is also ID(v), a cycle has been found:
-
Remove P from its list.
-
If ID(v) is the least ID of any ID in P, then add P to the Cycle List. (The purpose is to count each cycle only once.)
-
-
Else, if ID(v) is somewhere else in the path, then remove P from the path list (because this cycle must have been counted already).
-
Else, append ID(v) to the end of each of the remaining paths in its list.
-
Notes
On a large graph with undirected edges, Cycle Detection is likely to run out of memory. In addition, it will detect duplicate cycles that differ only in their direction.
Specifications
tg_cycle_detection ( SET<STRING> v_type_set, SET<STRING> e_type_set, INT depth,
BOOL print_results = TRUE, STRING file_path = "")Parameters
| Parameter | Description | Default |
|---|---|---|
|
Names of vertex types to use |
(empty set of strings) |
|
Names of edge types to use |
(empty set of strings) |
|
Maximum cycle length to search for, equal to the maximum number of iterations |
null |
|
If True, output JSON to standard output |
True |
|
If not empty, write output to this file. |
(empty string) |
Output
Computes a list of vertex ID lists, each of which is a cycle. The result is available in two forms:
-
streamed out to the console in JSON format
-
written to a file in tabular format