Internal Architecture
As the world’s first and only Native Parallel Graph (NPG) system, TigerGraph is a complete, distributed, graph analytics platform supporting web-scale data analytics in real time. The TigerGraph NPG is built around both local storage and computation, supports real-time graph updates, and works like a parallel computation engine. These capabilities provide the following unique advantages:
-
Fast data loading speed to build graphs - able to load 50 to 150 GB of data per hour, per machine
-
Fast execution of parallel graph algorithms - able to traverse hundreds of million of vertices/edges per second per machine
-
Real-time updates and inserts using REST - able to stream 2B+ daily events in real-time to a graph with 100B+ vertices and 600B+ edges on a cluster of only 20 commodity machines
-
Ability to unify real-time analytics with large scale offline data processing - the first and only such system
See the Resources section of our main website www.tigergraph.com to find white papers and other technical reports about the TigerGraph system.
System Overview
The TigerGraph Platform runs on standard, commodity-grade Linux servers. The core components (GSE and GPE) are implemented in C++ for optimal performance. TigerGraph system is designed to fit into your existing environment with a minimum of fuss.
-
Data Sources: The platform includes a flexible, high-performance data loader which can stream in tabular or semi-structured data, while the system is online.
-
Infrastructure: The platform is available for on-premises, cloud, or hybrid use.
-
Integration: REST APIs are provided to integrate your TigerGraph with your existing enterprise data infrastructure and workflow.
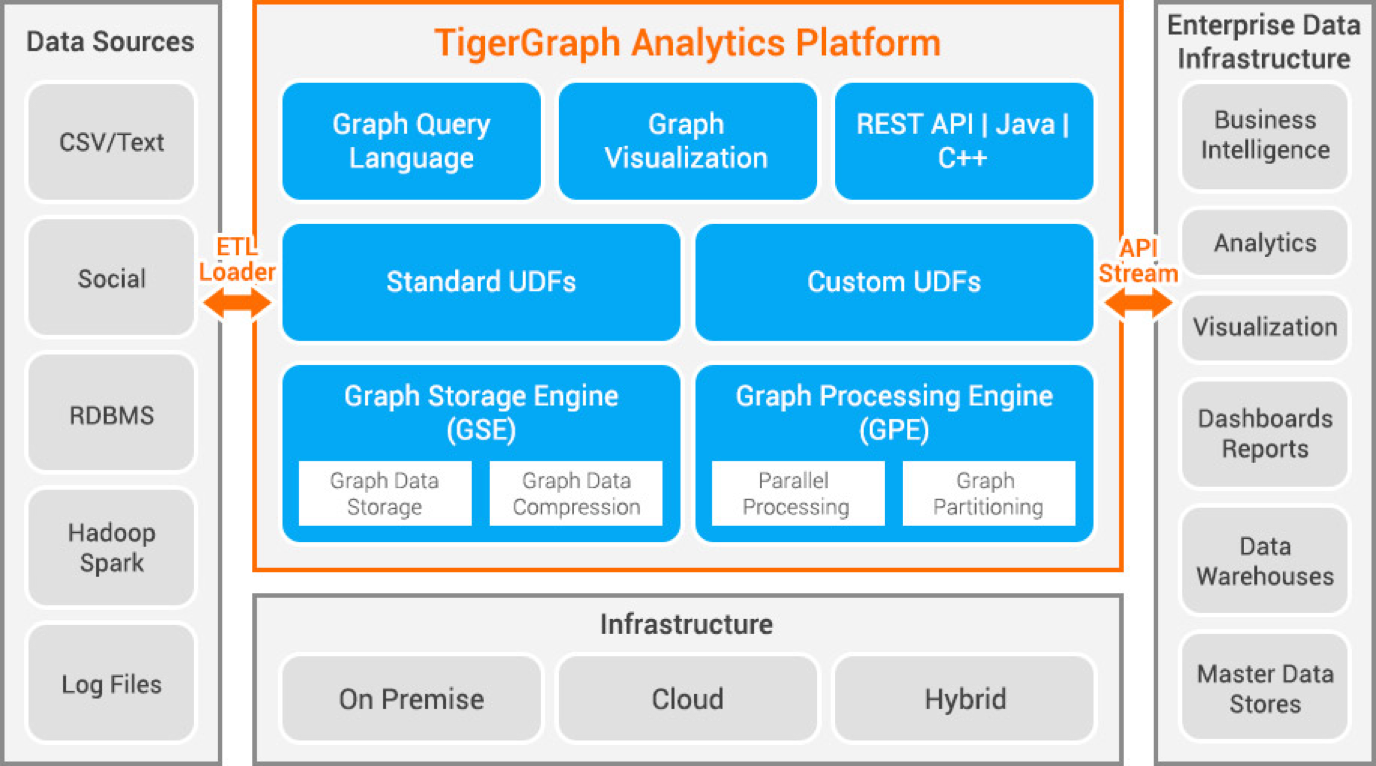
The figure below takes a closer look at the TigerGraph platform itself:
%20(2).png)
Within the TigerGraph system, a message-passing design is used to coordinate the activities of the components. RESTPP, an enhanced RESTful server, is central to the task management. Users can choose how they wish to interact with the system:
-
GSQL client: One TigerGraph instance can support multiple GSQL clients, on remote nodes.
-
GraphStudio: Our intuitive graphical user interface, which provides most of the basic GSQL functionality.
-
REST API: Enterprise applications which need to run the same queries many times can maximize their efficiency by communicating directly with RESTPP.
-
gAdmin is used for system administration.
Consult the Glossary for definitions of the TigerGraph services.