Schema Design Guide
Designing an effective graph schema is essential for building a scalable and efficient graph database. The primary goal is to model relationships between data entities that optimize both data retrieval and system resource usage. A well-structured schema ensures high performance both now and as data grows and queries become more complex.
This guide covers the key principles and best practices for schema design, explaining how to model relationships, handle data properties, and optimize queries. These best practices will help you make informed decisions for better performance and scalability, whether you’re working on a new schema or upgrading an existing one.
Components of a TigerGraph Schema
Vertices and Edges
In graph databases, vertices and edges are the building blocks of your schema. They define the structure of your data and how it is queried.
Vertices
Vertices represent entities or objects within your graph, such as people, products, companies, or locations. Think of vertices as nouns, things or concepts that are part of your data model. For example, a "Person" or a "Product" would be modeled as vertices.
The following schema creates a Person and a Product vertex:
CREATE VERTEX Person (PRIMARY_ID id INT, name STRING, age INT)
CREATE VERTEX Product (PRIMARY_ID id INT, name STRING, price FLOAT)Edges
Edges, on the other hand, represent relationships between entities. These relationships are the links that connect one vertex to another. For instance, an edge could represent that a Person "purchased" a Product, or that a Person "works_for" a Company. Edges are often model verbs connecting two nouns (vertices).
The following schema creates an edge to represent a purchased relationship:
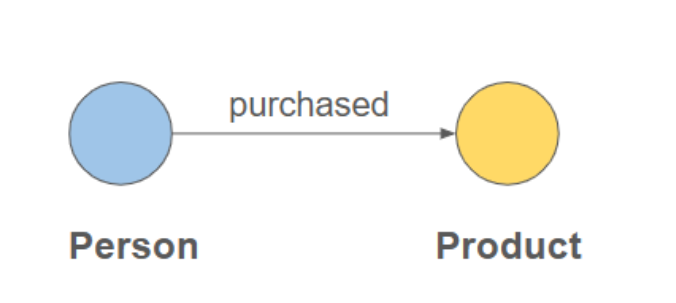
CREATE EDGE Purchased (FROM Person, TO Product, purchase_date DATE)The below figure shows how a 'Person' vertex is connected to a 'Product' vertex by a 'purchased' edge, representing a transactional relationship.
|
Options for Relationships
Choosing Edge Direction
When designing your schema, you must decide whether to use undirected, directed, or reversed edges. Each type of edge serves a specific purpose depending on how you intend to query and traverse the data.
Undirected Edges
Use undirected edges for bidirectional relationships. In a friendship relationship, for example, if Person A is friends with Person B, then Person B is also friends with Person A. This means the relationship works in both directions, and we don’t need to specify a direction for it.
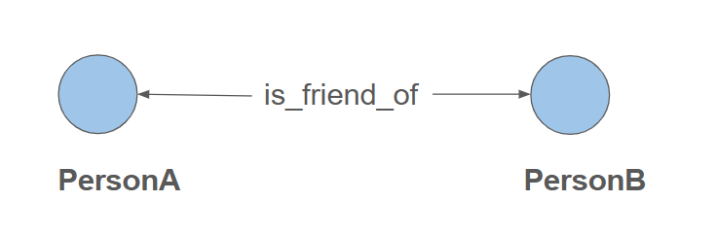
The following GSQL DDL statement creates an undirected edge for friendship:
CREATE UNDIRECTED EDGE Is_Friend_Of (FROM Person, TO Person)Directed Edge
Directed edges are used for one-way relationships where the direction of the relationship matters. For instance, in a work relationship, Person A might work for Company B, but Company B does not work for Person A. This clearly defines that the relationship flows only from Person A to Company B.
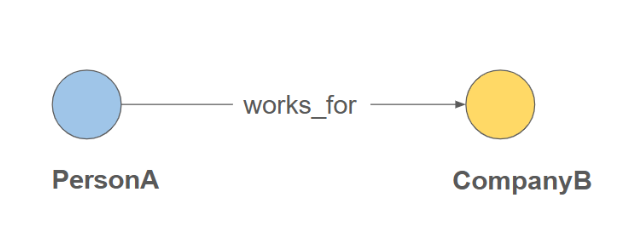
The following schema creates a directed edge for work relationship:
CREATE DIRECTED EDGE Works_For (FROM Person, TO Company)Reversed Edge
A reversed edge allows you to traverse a directed edge in the opposite direction of its semantic flow. For example, in a parent-child relationship, we might define the primary edge as "parent_of" (Parent → Child). However, to easily traverse the relationship in the opposite direction (from Child to Parent), we can use a reversed edge with a different name, like "child_of" (Child → Parent). This makes it easy to query in either direction.
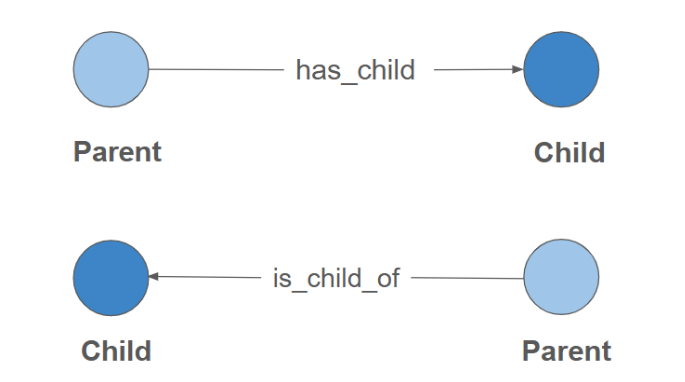
TigerGraph has built-in syntax to define a reserved edge that maintains the same attribute values as its primary edge. The following schema creates a directed edge plus a reserved edge for a parent-child relationship:
CREATE DIRECTED EDGE Parent_Of (FROM Person, TO Person) WITH REVERSE_EDGE = "Child_Of"Multiple Relationships Between Two Vertices
For situations where different types of relationships occur between two vertices (e.g., purchases and reviews, or purchases and returns), you can represent each relationship as a discriminated edge.
The figure below shows a 'Person' vertex connected to a 'Product' vertex by two different edges: 'purchased' and 'returned'. Each edge clearly indicates a different type of interaction.
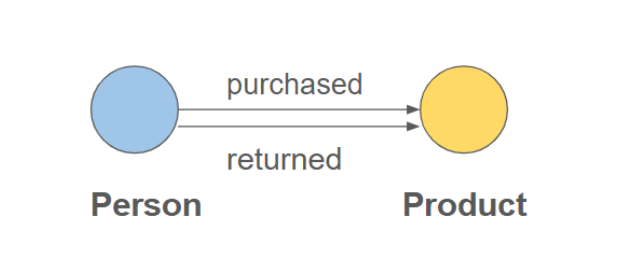
The following scheme creates discriminated edges to represent different types of events (e.g., purchase and return):
CREATE EDGE Purchase_Event (FROM Person, TO Product, purchase_date DATETIME, quantity INT)
CREATE EDGE Return_Event (FROM Person, TO Product, return_date DATETIME, reason STRING)Indexing - Optimizing Searches
Efficient querying relies on optimizing how the data is indexed. When you design a graph schema, proper indexing plays a key role in speeding up searches.
Vertex Indexes
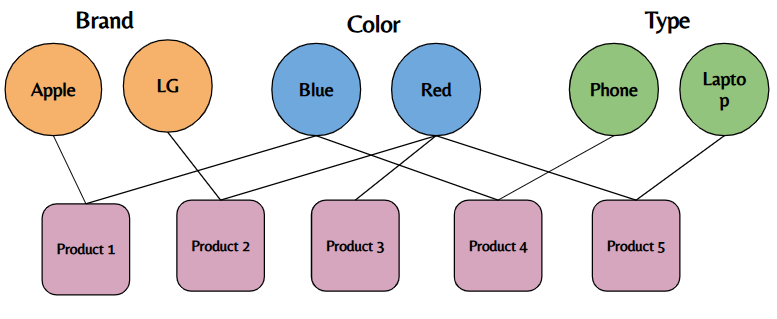
A vertex index is a design pattern where you model frequently grouped or filtered attributes such as color, brand, or type as their own vertex types instead of simple attributes. This lets you easily search or filter, for example, all products that are red or from a specific brand.
In the figure below, "Brand", "Color", and "Type" are vertex types connected to products, making filtering and grouping by these properties efficient and flexible.
Secondary Indexes
Use secondary indexes when the search behavior justifies having an index and either range queries are needed or a vertex index is not appropriate.
Optimizing for Your Use Case
Attributes - Property or Vertex Type
When defining the properties of entities, you must decide whether to model them as attributes or vertices.
Attributes
Attributes are properties that are directly associated with vertices or edges (e.g., product color, transaction date).
Vertices
Model properties as vertices when they are frequently queried or need to be linked to multiple other vertices (e.g., color as a vertex for products).
Granularity of Edge Types
When deciding how detailed your relationships should be, you have two options: multiple edge types or a single edge type with attributes.
Multiple Edge Types
If your relationship types are well-defined and not to numerous (e.g., "is_friend_of", "is_colleague_of"), use multiple edge types.
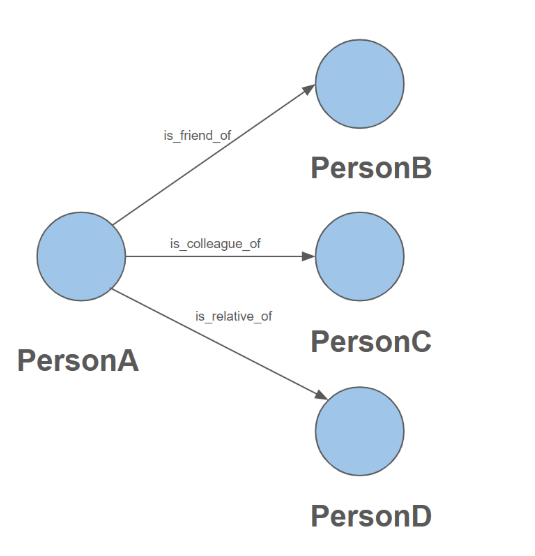
The following schema creates multiple edge types for relationships like friend and colleague:
CREATE UNDIRECTED EDGE Is_Friend_Of (FROM Person, TO Person)
CREATE UNDIRECTED EDGE Is_Colleague_Of (FROM Person, TO Person)Single Edge Type with Attributes
Alternatively, you can use one generic edge type (e.g., "is_related_to") and use an attribute to define the relationship (e.g., "friend", "colleague").
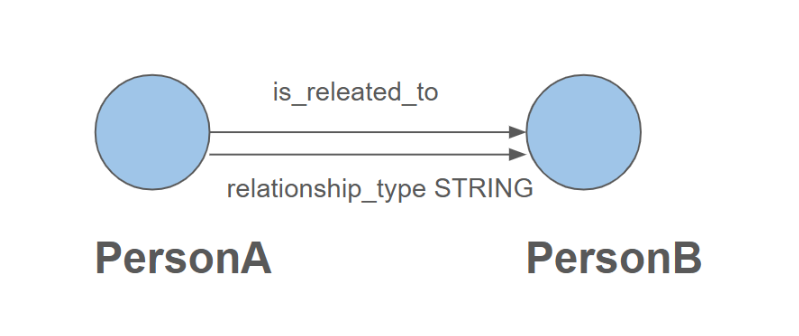
The following schema uses a single edge type with an attribute for relationship type:
CREATE DIRECTED EDGE Is_Related_To (FROM Person, TO Person, relationship_type STRING)
|
Modeling Time
Time is often an essential element in graph schemas, particularly for event-based queries.
Modeling Time Hierarchically
Model time as a hierarchy of vertices, like Year → Month → Day, for efficient querying of time-based data.
This structure allows for faster time series querying speed by creating hierarchical datetime structures. The levels and partitioning of each level can be customized to best suit your specific use case.
This organized time model helps us quickly find things, for example, like finding all products made in the first 15 days of February 2025.
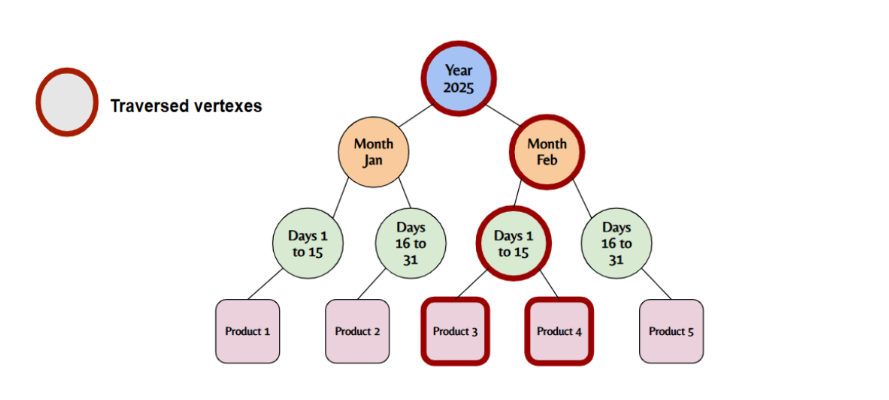
The following schema creates the necessary time vertices and their relationships:
// 1. Define Vertex Types:
CREATE VERTEX Year (PRIMARY_ID year_val INT);
CREATE VERTEX Month (PRIMARY_ID month_val INT, month_name STRING);
CREATE VERTEX Day (PRIMARY_ID day_val INT);
CREATE VERTEX Product (PRIMARY_ID product_id STRING);
// 2. Define Edge Types to establish hierarchy and relationships:
// Connects a Year to its Months
CREATE DIRECTED EDGE HAS_MONTH (FROM Year, TO Month);
// Connects a Month to its Days
CREATE DIRECTED EDGE HAS_DAY (FROM Month, TO Day);
// Connects a Product to a specific Day (where an event related to the product occurred)
CREATE DIRECTED EDGE PRODUCED_ON (FROM Product, TO Day);Focal Hub
A focal hub is a central vertex that connects to many other vertices via multiple edges. It can become a performance bottleneck in your schema.
Use Case-Based Schema Design
Graph schema design should always reflect your use case and query requirements. The type of relationships you need to track will guide your choice of schema design.
Event-Centered Schema
This design focuses on events as the central element of your application. It’s ideal for use cases where you need to analyze event-driven data. For example, in an e-commerce platform, events like purchases, returns, or reviews could be central to understanding the relationships between customers and products.
For example, in an e-commerce schema, purchases and product reviews would be modeled as key events, with relationships showing how customers interact with products.
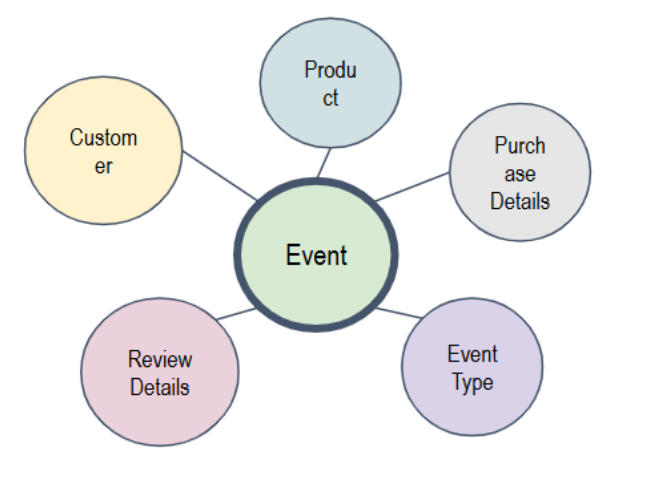
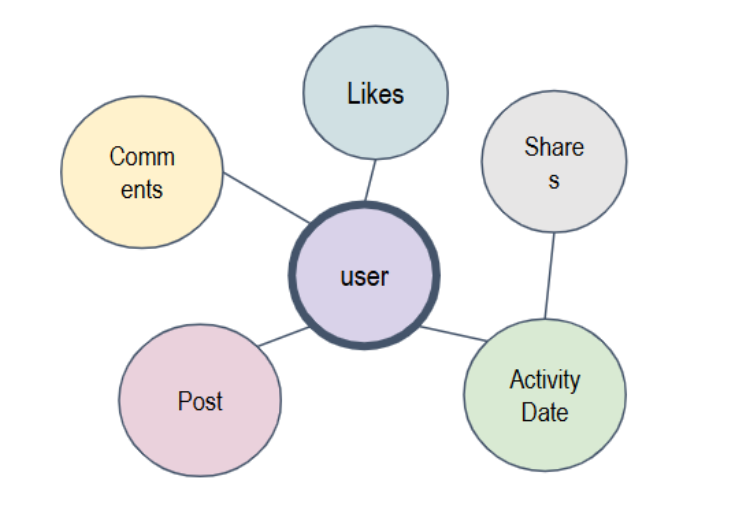
User-Centered Schema
This design focuses on user behavior and interactions, making it ideal for applications like social networks or user analytics. In a user-centered schema, you would model users and their relationships with products, services, or other users.
For example, in a social network schema, you could model user interactions (such as comments, likes, and shares) and track user behavior over time.
|
Recommendation
Here are some key recommendations for schema design:
-
Edge Types: Use multiple edge types when specificity is important; for simpler designs, use a single edge type with attributes.
-
Attributes vs. Vertices: Model frequently queried properties as vertices and use attributes for less critical data.
-
Events: Model events as vertices when they have properties like timestamps, types, or need to be queried individually. For simple cases, use edge attributes to add event details between two related vertices.
-
Schema Design: Choose an event-centered or user-centered schema based on the primary query focus.
-
Indexing: Use secondary indexes for range queries and vertex indexes for high-cardinality attributes.
Following these best practices ensures your TigerGraph schema delivers fast, efficient queries and scales with your data and application needs.