Exception Statements
This section describes how the GSQL language responds to exceptions and supports user-defined exception handling . An exception is a run-time error. The GSQL language supports both built-in system exceptions and user-defined exceptions. Built-in exceptions include GSQL language exceptions (such as out-of-range value, wrong data type, and illegal operation), and errors arising in other TigerGraph components or from the operation system.
The GSQL query language also supports user-defined exception responses, also known as exception handling. This section covers the following syntax for user-defined exception behavior:
#########################################################
## Exception Statements ##
declExceptStmt := EXCEPTION exceptVarName "(" errorCode ")"
exceptVarName := name
errorCode := integer
raiseStmt := RAISE exceptVarName [errorMsg]
errorMsg := "(" expr ")"
tryStmt := TRY queryBodyStmts EXCEPTION caseExceptBlock+
[elseExceptBlock] END ";"
caseExceptBlock := WHEN exceptVarName THEN queryBodyStmts
elseExceptBlock := ELSE queryBodyStmtsDefault Exception Response
When an exception occurs during the execution of a query, the default response is the following:
-
The query will not execute any more statements; it will exit.
-
If the query was run using the RUN QUERY command, then an error message will be displayed.
-
If the query was run by invoking the GET /query REST++ endpoint, then the output will be a simple JSON object. Some errors have a error "code" field; others do no t:
{
"error": true,
"message": "<errorMsg>"
"code": "<errType><errorCode>"
}The example below show two common errors: wrong data type and divide-by-zero. First we define a simple query that divides 100.0 by the query’s input parameter.
CREATE QUERY excpBuiltin(INT n1) FOR GRAPH Minimal_Net {
PRINT 100.0/n1;
}We then test three cases:
-
A valid input (such as n1 = 7)
-
Wrong data type (n1 = "A")
-
Divide by zero (n1 = 0)
First we test using the GSQL interface. When the query runs without error, the output is in JSON format. Where there is a built-in exception, however, only an error message is displayed.
GSQL > RUN QUERY excp_builtin(7)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"100.0/n1": 14.28571}]
}
GSQL > RUN QUERY excp_builtin("a")
Values of parameter n1 must be INT64 type, invalid value [a] provided.
GSQL > RUN QUERY excp_builtin(0)
Runtime Error: divider is zero.The situation is a little different when running the query as a REST++ endpoint. The output is always in JSON format.
|
As of TigerGraph v1.2, the format for the GET /query endpoint has changed. The graph name must now be specified after /query: |
$ curl -X GET "http://localhost:14240/restpp/query/minimalNet/excpBuiltin?n1=7"
{
"error": false,
"message": "",
"results": [
{
"100.0/n1": 14.28571
}
],
"version": {
"edition": "developer",
"api": "v2",
"schema": 0
}
}
$ curl -X GET "http://localhost:14240/restpp/query/minimalNet/excpBuiltin?n1=a"
{
"code": "REST-30000",
"error": true,
"message": "Values of parameter n1 must be INT64 type, invalid value [a] provided.",
"version": {
"edition": "developer",
"api": "v2",
"schema": 0
}
}
$ curl -X GET "http://localhost:14240/restpp/query/minimalNet/excpBuiltin?n1=0"
{
"error": true,
"message": "Runtime Error: divider is zero.",
"version": {
"edition": "developer",
"api": "v2",
"schema": 0
}
}Exception format not defined in query
A default exception format is available in cases where the exception is not defined in the query.
-
Exception <name> is raised with an error code of <code>.
create or replace query test_q(bool b) {
EXCEPTION UsedFalseBoolean (80005);
if not b then
raise UsedFalseBoolean; // EXCEPTION message not defined here.
end;
print "Used true boolean in main.";
}
install query test_q
run query test(false)
Exception UsedFalseBoolean is raised with error code 80005User-Defined Exception Behavior
A query author can specify what should be the response if a particular type of exception occurs within a particular specified block of statements.
The following statement types are available to specify a user-defined exception condition or a user-defined exception response.
-
The EXCEPTION Declaration Statement names a user-defined exception.
-
The RAISE Statement indicates that one of the user-defined exceptions has occurred.
-
The TRY…EXCEPTION Statement is used to define and apply user-defined exception handling to a block of query-body statements. This can be used with or without preceding user-defined EXCEPTION and RAISE statements.
|
Built-in exceptions always take precedence over user-defined exceptions. Therefore, user-defined exceptions can only be used to catch conditions that would not be caught by a built-in exception. This means that built—in exceptions are best used to capture situations which are legal according to the general syntax and semantics of the GSQL query language, but which are illegal or undesirable for a particular user application. |
EXCEPTION Declaration Statement
declExceptStmt := EXCEPTION exceptVarName "(" errorCode ")"
exceptVarName := name
errorCode := integerTo use a user-defined exception, it must first be declared. An exception declaration statement declares a user-defined exception type, assigning a name and identification number. The id number errorCode must be greater than 40,000. Numbers 40,000 and lower are reserved for system exceptions. Exception statements must be placed before any query-body statements, after accumulator declaration statements . A query can declare multiple exception types.
RAISE Statement
raiseStmt := RAISE exceptVarName [errorMsg]
errorMsg := "(" expr ")"The RAISE statement announces that a user-defined exception has just occurred. The exceptVarName must match one of the exceptions that was previously declared. An optional error message can be specified. Once the RAISE statement is executed, the flow of execution changes. If the RAISE statement is not within a TRY clause, then the query ends with the default exception response, using the error code and error message defined by the exception type and RAISE statements. If the RAISE is within a TRY statement, then execution jumps to the EXCEPTION handling clause of the TRY statement.
A RAISE statement itself does not include the conditions that define the exception. Typically, the user will use an IF…THEN statement and place the RAISE statement within the THEN clause.
|
In the current version, a RAISE statement can only be used as a query-body-statement. It cannot be used as a DML-sub-statement. In particular, you cannot RAISE an exception inside a SELECT statement. |
The example below defines and checks for two types of exceptions: an empty input set (40001) and no matching edges (40002). Remember that the minimum allowed code number is 40001.
CREATE QUERY excp_count_activity(SET<VERTEX<Person>> v_set, STRING e_type) FOR GRAPH Social_Net {
/* Count how many edges there are from each member of the input person set to posts, along the specified edge type. */
MapAccum<STRING,INT> @@all_count;
EXCEPTION empty_list (40001);
EXCEPTION no_edges (40002);
IF ISEMPTY(v_set) THEN
RAISE empty_list ("Error: Input parameter 'v_set' (type SET<VERTEX<Person>>) is empty");
END;
Start = v_set;
Results = SELECT s
FROM Start:s -(:e)- post:t
WHERE e.type == e_type
ACCUM @@all_count += (t.subject -> 1);
IF Results.size() == 0 THEN
RAISE no_edges ("Error: No '" + eType + "' edges from the vertex set");
END;
PRINT @@all_count;
}// Valid input: no exceptions
$ curl -X GET "http://localhost:14240/restpp/query/socialNet/excpCountActivity?v_set=person2&vSet=person6&eType=posted"
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{
"@@allCount": {
"cats": 1,
"tigergraph": 2
}
}]
}
// empty input set (due to spelling error in parameter name)
$ curl -X GET "http://localhost:14240/restpp/query/socialNet/excpCountActivity?vset=person2&vset=person6&eType=posted"
{
"code": "40001",
"error": true,
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"message": "Error: Input parameter 'vSet' (type SET<VERTEX<person>>) is empty"
}
// no edges (due to unknown edge type)
$ curl -X GET "http://localhost:14240/restpp/query/socialNet/excpCountActivity?vSet=person2&vSet=person6&eType=commented"
{
"code": "40002",
"error": true,
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"message": "Error: No 'commented' edges from the vertex set"
}TRY…EXCEPTION Statement for Custom Error Handling
tryStmt := TRY queryBodyStmts EXCEPTION caseExceptBlock [elseExceptBlock] END ";"
caseExceptBlock := WHEN exceptVarName THEN queryBodyStmts+
elseExceptBlock := ELSE queryBodyStmtsThe TRY…EXCEPTION Statement is used to define and apply user-defined exception handling to a block of query-body statements.
A TRY…EXCEPTION statement can be nested within a TRY block or EXCEPTION block.
|
The current version of GSQL does not support custom handling of built-in exceptions.
Therefore, if a built-in exception occurs, it ignores the |
The TRY…EXCEPTION Statement is a compound statement containing two blocks.
The first block (TRY) consists of the query-body statements for which custom error handling should be applied.
The second block (EXCEPTION) contains a series of WHEN…THEN exception handling clauses.
Each exception handling clause names an exception type and specifies what actions to take in the event of the exception.
An optional ELSE clause contains handling statements for all other exceptions.
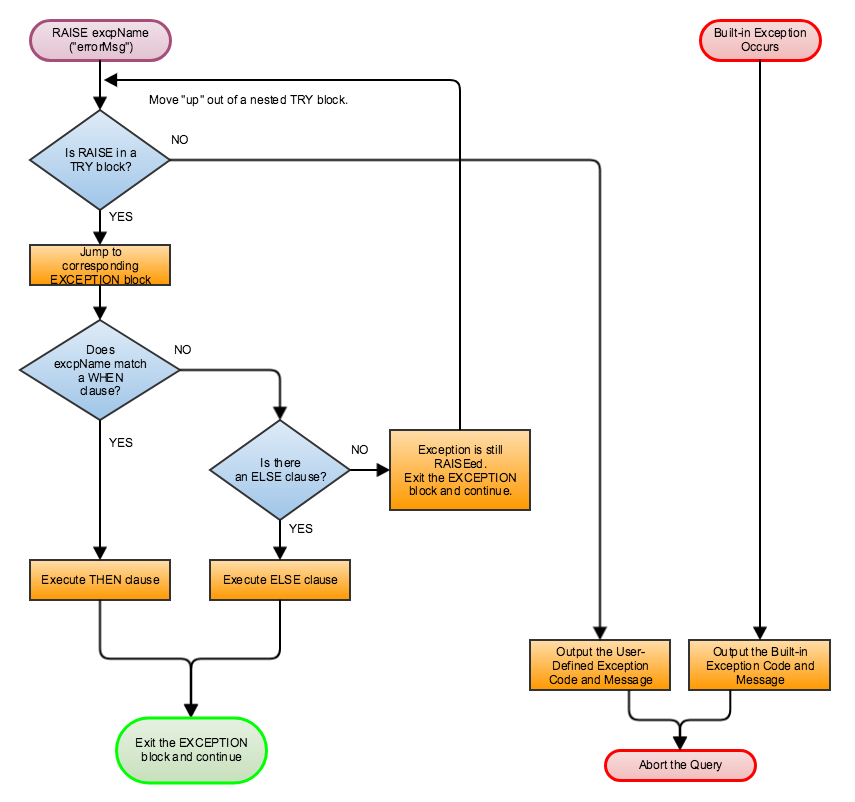
The following text and visual flowchart details how the TRY… EXCEPTION block handles an exception.
When an exception occurs within a TRY block, the flow of execution skips the remainder of the TRY block and jumps to the EXCEPTION block. The GSQL flow now seeks to match the exception type with a handler. After executing the handling statements in the THEN or ELSE clause, the flow skips the remainder of the EXCEPTION block and continues with the statement following the END statement. However, if there is no matching WHEN or ELSE handler, then the exception is propagated. That is, the RAISE state is maintained after exiting the EXCEPTION block. If the TRY…EXCEPTION block is nested inside another TRY block, then the handling process is repeated at this upper level. This repeats until either the exception is handled or there are no more TRY…EXCEPTION blocks.
Finally, if the unhandled exception is not within a TRY block, then the query is aborted, and the default exception response is the output.
.png)
Case 1: If cond1 is true in the outer TRY block,
-
RAISE A and jump to the output EXCEPTION block.
Handled by ELSE HandStmtsZ.
Case 2: If cond2 is true in the inner TRY block,
-
RAISE A and jump to the inner EXCEPTION block.
Handled by handStmtsX;
Case 3: If cond3 is true in the inner TRY block,
-
RAISE B and jump to the inner EXCEPTION block. There is no matching handler here, so propagate the exception. Jump to the outer EXCEPTION block. Handled by handStmtsY.
Custom Handling Example:
The following example is a modified shortest path query. It looks for all paths from a source to a target in a computer network. It uses breadth-first search and stops at depth N when it has found at least one path at depth N, or it has searched the entire graph. There are three conditions which will cause it to RAISE an exception and abort the search:
-
Seeing an edge with a negative connection speed (because the graph has bad data).
-
Seeing an edge with a very slow connection speed (again because the graph has bad data).
-
If no path was found in the graph (the search is already over, but we skip printing results).
Note that cases 1 and 2 do NOT mean that a negative or slow speed edge is actually on a shortest path, only that the query noticed a bad edge during its search. Also, because we cannot RAISE within the SELECT block, we use a workaround: set an integer variable with an error code. Immediately after the SELECT block, test the integer variable and RAISE exceptions as needed.
CREATE QUERY comp_path_valid (VERTEX<Computer> src, VERTEX<Computer> tgt, BOOL en_excp) FOR GRAPH Computer_Net {
/* Find valid paths in a computer network from a source to a target.
Stop search once you have found some paths.
3 Exceptions: (1) Negative connection speed, (2) Slow connection speed, (3) No path.
Set en_excp=true to raise exceptions. en_excp=false will find paths, good or bad. */
OrAccum @@reached, @visited;
ListAccum<STRING> @paths;
DOUBLE min_speed = 0.4;
INT err;
EXCEPTION neg_speed (40001);
EXCEPTION slow_speed (40002);
EXCEPTION not_reached (40003);
TRY
Start = {src};
// Initialize: path to src is itself.
Start = SELECT s
FROM Start:s
ACCUM s.@paths = s.id;
WHILE Start.size() != 0 AND NOT @@reached DO
Start = SELECT t
FROM Start:s -(:e)- :t
WHERE t.@visited == false
ACCUM CASE
WHEN e.connection_speed < 0 THEN err = 1
WHEN e.connection_speed < min_speed THEN err = 2
WHEN t == tgt THEN @@reached += true
END,
// List1 * List2 -> List(each elem of List1 concat w/each elem of List2)
t.@paths += (s.@paths * ["~"]) * [t.id]
POST-ACCUM t.@visited = true;
IF err == 1 AND en_excp THEN
RAISE neg_speed ("Negative Speed");
ELSE IF err == 2 AND en_excp THEN
RAISE slow_speed ("Slow Speed");
END;
END;
IF NOT @@reached AND en_excp THEN
RAISE not_reached ("No path to target");
ELSE
result = {tgt};
PRINT result[result.@paths];
END;
EXCEPTION
WHEN neg_speed THEN PRINT "bad path: negative speed";
WHEN slow_speed THEN PRINT "bad path: slow speed";
WHEN not_reached THEN PRINT "no path from source to target";
END;
}As the data in Appendix D show:
-
Any search passing through c1 will see negative edges.
-
Any search passing through c12 will see negative and slow edges.
-
Any search passing through c14 will see negative edges.
The results for 5 cases are shown: 1 valid search plus each of the 3 exception conditions. The 5th case is the same as the 4th, but exception handling is not enabled.
GSQL > RUN QUERY compPathValid("c10","c12",true)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"Result": [{
"v_id": "c12",
"attributes": {"Result.@paths": ["c10~c11~c12"]},
"v_type": "computer"
}]}]
}
GSQL > RUN QUERY compPathValid("c1","c12",true)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"bad path: negative speed": "bad path: negative speed"}]
}
GSQL > RUN QUERY compPathValid("c10","c13",true)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"bad path: slow speed": "bad path: slow speed"}]
}
GSQL > RUN QUERY compPathValid("c24","c25",true)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"no path from source to target": "no path from source to target"}]
}
GSQL > RUN QUERY compPathValid("c24","c25",false)
{
"error": false,
"message": "",
"version": {
"edition": "developer",
"schema": 0,
"api": "v2"
},
"results": [{"Result": [{
"v_id": "c25",
"attributes": {"Result.@paths": []},
"v_type": "computer"
}]}]
}